複雑な問題解決に特化したAI、o1-previewとその可能性について解説します。
1分でわかる動画で解説
OpenAI o1-preview (コードネーム: Strawberry) とは?
OpenAI o1-previewは、コードネーム「Strawberry」として知られる画期的なAI推論モデルシリーズです。2024年9月12日にリリースされ、科学、コーディング、数学などの複雑な問題に取り組むために開発されました。強化された推論と問題解決能力に重点を置き、人工知能の可能性を大きく広げるものです。
o1-previewの仕組み:人間の思考プロセスを模倣
o1-previewモデルは、、「Chain of Thoughts(思考の連鎖)」と「Self Reflection(自己反省)」という手法を用いて、回答を生成する前により多くの時間を「考える」ことに重点を置いてトレーニングされています。
このアプローチは人間の認知プロセスを模倣しており、モデルは自身の思考を洗練させ、様々な戦略を探り、間違いを認識できます。外部からの指示なしに内部的に多段階推論と自己反省を行うことで、o1-previewはより正確で信頼性の高い解決策を導き出せます。
思考の連鎖
1. 問題を小さなステップに分解
2. 各ステップを論理的に分析
3. ステップ間の関係を理解
4. 最終的な解決策に向けて段階的に推論を進める
自己反省
1. 結論に至るまでの思考プロセスを評価
2. 誤りや矛盾点を特定
3. 必要に応じて、異なるアプローチを試みる
4. 解決策の精度と信頼性を向上させる
o1-previewの主な能力
OpenAI o1-previewは、様々な難題において目覚ましい進化を遂げています。
数学
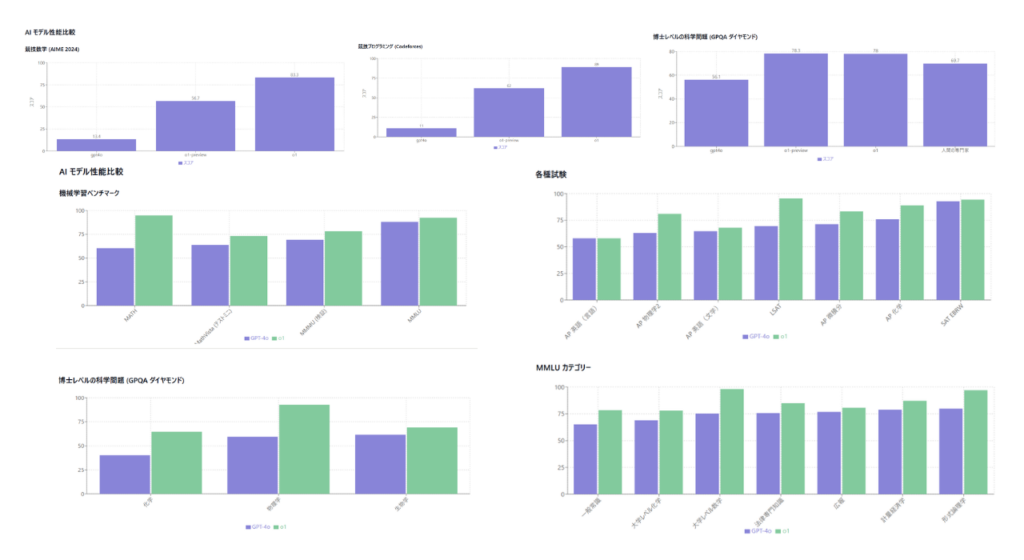
アメリカ数学会 (AIME) の予選試験で、o1-previewは問題の83%を解き、GPT-4oの13%から大幅に向上しました。
コーディング
Codeforcesの競技会で上位89%にランクインし、高度なコーディング能力を示しました。
科学
物理学、化学、生物学の難しいベンチマークタスクで、博士課程の学生と同等の成績を収め、約75~80%の正答率を達成しました。
o1-previewとGPT-4oとの比較
以下の表は、o1-previewがGPT-4oと比較してどれだけ性能が向上しているかを示しています。
エージェント評価と安全性
OpenAIは、モデルの自律性、説得能力、サイバーセキュリティ応用、潜在的な壊滅的リスクを評価するために、新しい評価手順を導入しました。o1-previewは、サイバーセキュリティのリスクが低く、壊滅的なシナリオのリスクが中程度である一方、高度な推論能力により、安全性と整合性に関するガイドラインの遵守に優れています。
o1-previewは自己反省機能を用いて安全プロトコルを守るため、ジェイルブレイクの試みや不正操作に対する耐性が高くなっています。従来のハッキングやジェイルブレイクは、モデルの内部安全チェックと整合性ガイドラインの遵守により、効果が薄くなっています。
プロンプトエンジニアリングへの影響
o1-previewの登場は、ユーザーが大規模言語モデル(LLM)と対話する方法に大きな変化をもたらします。
プロンプトの簡素化
ユーザーは、「段階的に考えて」といった複雑なプロンプトを作成したり、プロンプトエンジニアリング技術を使う必要がなくなりました。モデルは本質的に内部推論を行うため、ユーザーの入力要件が簡単になります。
理解力の向上
モデルは、簡潔で明確な指示を効果的に解釈できるため、広範な説明や文脈は不要になります。
o1-miniの特徴
OpenAI o1-miniは、コーディングタスクに最適化された、より高速で費用対効果の高いo1シリーズのバージョンです。o1-previewよりも80%も安価なため、広範な世界知識を必要としない推論を必要とするアプリケーションに適しています。
複雑な推論においてo1-previewに匹敵するものではないかもしれませんが、o1-miniは複雑なコードの正確な生成とデバッグに優れています。
このモデルは、o1-previewと比較して週ごとのメッセージ制限が高いChatGPT Plusユーザーが利用できます。また、ユーザーはモデルの広範な内部推論プロセスに対してお金を払いますが、開発者にとっては予算に優しい選択肢となります。
価格と入手方法
ChatGPT Plusユーザー
o1-previewとo1-miniはどちらも、手動でモデルを選択できます。
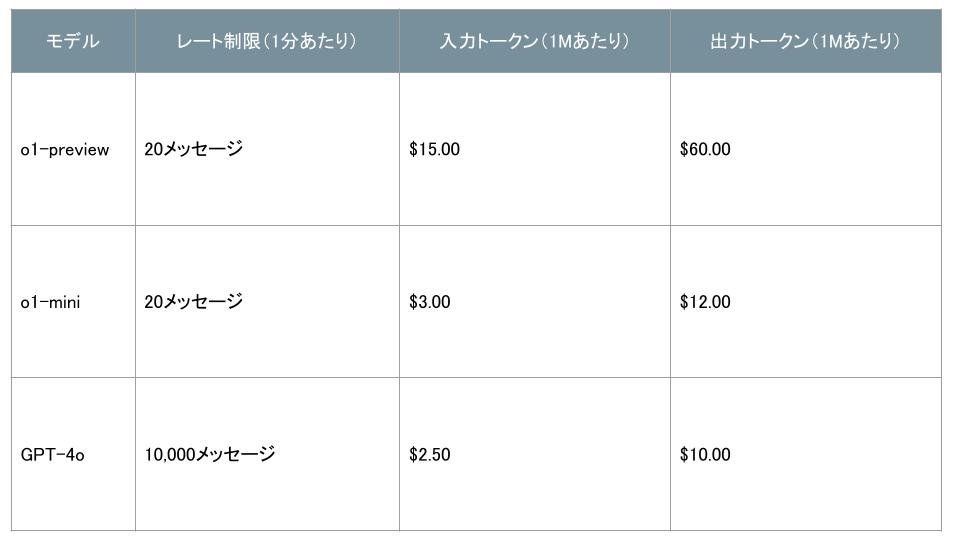
リリース当初は、週ごとのレート制限はo1-previewが30メッセージ、o1-miniが50メッセージとなっています。OpenAIはこれらのレートを引き上げ、ChatGPTが与えられたプロンプトに対して自動的に適切なモデルを選択できるようにすることを目指しています。

開発者
API使用ティア5の資格を持つ開発者は、1分あたり20リクエストのレート制限で、両方のモデルのプロトタイピングを開始できます。APIは現在、関数呼び出し、ストリーミング、システムメッセージをサポートしていません。
開発者は、統合の詳細についてはAPIドキュメントを参照できます。
今後の展望
OpenAIは、o1-previewにさらなる機能を追加して強化することを計画しています。
– 今後の機能としては、情報のウェブ検索や、ファイルや画像のアップロードなどが挙げられます。
– モデルの推論時間は、数分から数時間、あるいは数日にまで延長される見込みであり、より複雑な問題解決が可能になります。
– 今後のアップデートでは、モデルのコンテキストが現在の128kトークンの制限を超えて拡張される可能性があります。
注記:100トークンは、約75単語に相当します。
結論
OpenAIのo1-previewは、AI推論モデルにおける大きな進歩であり、深い推論と問題解決能力を必要とする複雑なタスクにおいて優れたパフォーマンスを提供します。このモデルは、複雑なプロンプトエンジニアリングの必要性をなくすことでユーザーとのやり取りを簡単にし、悪用を防ぐための安全対策を強化しています。
o1-previewのようなAIモデルは、今後ますます複雑なタスクに取り組むようになり、特定の分野では人間の専門家を超える可能性も秘めています。AI推論モデルは、様々な業界において不可欠な存在となり、生産性とイノベーションを向上させることが期待されています。AIの能力が高まるにつれて、倫理的な使用と安全性がさらに重要となり、強固なガイドラインと監督が必要となります。
よくある質問
Q: OpenAI o1-previewは従来のモデルと比べて何が違うのですか?
A: o1-previewは、応答する前により多くの時間を「考える」ように設計されており、複雑な問題をより正確に解決するために、内部的な多段階推論と自己反省機能を利用しています。
Q: o1-previewで最良の結果を得るためには、特別なプロンプトを使用する必要がありますか?
A: いいえ、このモデルは、「段階的に考えて」といったプロンプトエンジニアリング技術を必要とせずに、シンプルで明確な指示を理解できるように最適化されています。
Q: o1-previewはどのように安全性を確保し、悪用を防いでいるのですか?
A: このモデルは、新しい安全トレーニングアプローチを採用しており、推論能力を活用して安全ガイドラインを守り、ジェイルブレイクの試みに抵抗します。
Q: o1-previewは、すべてのタスクにおいてGPT-4oに取って代わるものですか?
A: o1-previewは、数学やコーディングなどの推論を多用するタスクに優れていますが、広範な世界知識や言語の多様性を必要とする分野では、GPT-4oの方が優れた性能を発揮する場合があります。
Q: 開発者はAPIを介してo1-previewにどのようにアクセスできますか?
A: API使用ティア5の資格を持つ開発者は、一定の制限付きでo1-previewにアクセスできます。詳細については、OpenAIのAPIドキュメントを参照してください。






