更新日:2025年11月7日
1. デスクトップアプリのインストール~利用開始までの手順
1-1. アプリのインストール、アクティベート
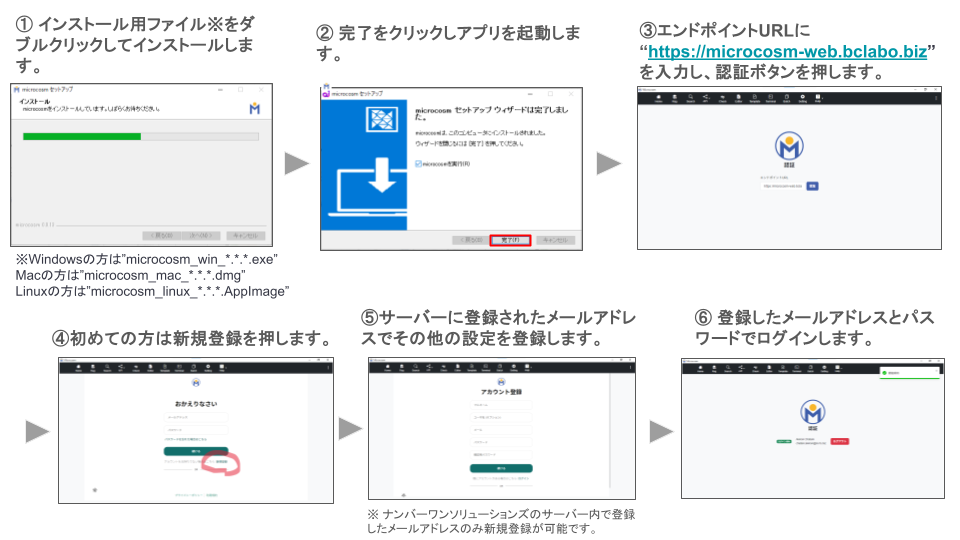
※エンドポイントURL:https://microcosm-web.bclabo.biz
※2回目以降の起動方法…デスクトップに設置された下記アイコンをダブルクリックしてアプリを起動します。

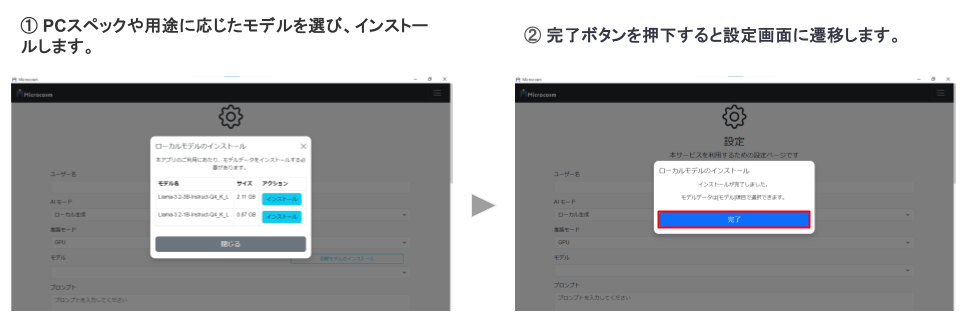
1-2. ローカルモデルのインストール
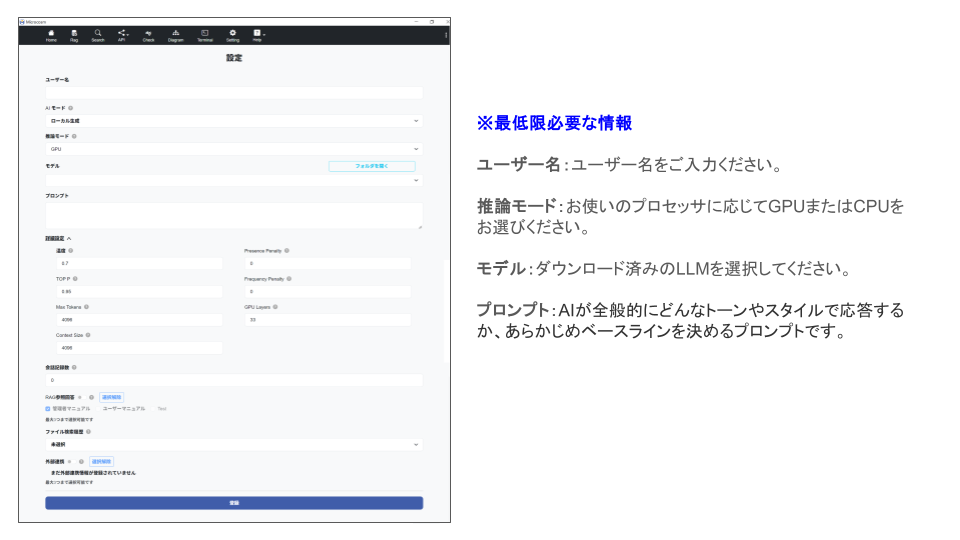
1-3. プロンプト等の設定
設定画面にて、必要な情報を設定します。
※最低限必要な情報を入力することで登録を行えますが、各項目の詳細な設定を行いたい方は2-2. 設定画面をご参照ください。
※最低限必要な情報
ユーザー名:ユーザー名をご入力ください。
推論モード:お使いのプロセッサに応じてGPUまたはCPUをお選びください。
モデル:ダウンロード済みのLLMを選択してください。
プロンプト:AIが全般的にどんなトーンやスタイルで応答するか、あらかじめベースラインを決めるシステムプロンプトです。(例)『常に丁寧な口調で答えて』や『出力は箇条書きで簡潔に』」
プロンプト例
#指示
あなたはAI事業戦略のブレインです。
私からの質問に対して、要点を絞って回答してください。
#制約
ビジネス会話を意識し、丁寧かつ自然な日本語で回答を生成してください。
回答はRAGデータのテキスト通りに生成してください。
RAGデータにない情報を推測で補わないでください。
出力文字数は以下を守ってください。
下限:10文字
上限:200文字
1-4. 利用開始
以下ホーム画面から会話を開始できます。

2. 各種機能説明
2-1. ホーム画面

| ① Home | ホーム画面に戻ります。 |
| ② Rag | RAG一覧画面に遷移します。 |
| ③ Search | AIファイル検索画面に遷移します。 |
| ④ API | 外部連携またはローカルAPI表示画面に選択遷移します。 ローカルAPIは、独自サーバ上で稼働させているMicrocosmアプリに各クライアントPCから接続するための機能です。 ※ローカルAPIはオプション機能です。 |
| ⑤ Check | 誤字脱字チェック画面に遷移します。 |
| ⑥ Editor | Editor画面が別ウィンドウで開きます。 |
| ⑦ Template | テンプレート作成画面に遷移します。 |
| ⑧ Terminal | 開発中の機能です。 |
| ⑨ Batch | 開発中の機能です。 |
| ⑩ Setting | 設定画面へ遷移します。 |
| ⑪ Help | プロンプト集:参考にできるプロンプト例を確認できるページへ遷移します。マニュアル:Microcosmユーザーマニュアルのページへ遷移します。 お問い合わせ:お問い合わせ用Googleフォームへ遷移します。 使用のためには、インターネット接続が必要な機能です(アプリ内の情報が漏洩することはありません)。 |
| ⑫ スレッド表示 | スレッドの一覧を表示します。 |
| ⑬ ナレッジビュー機能 | ナレッジビュー機能の画面に遷移します。 |
| ⑭ エージェント検索 | エージェント検索画面に遷移します。 |
| ⑮ モデルダウンロード | モデル一覧画面に遷移します。 |
| ⑯ 認証 | 認証画面に遷移します。 |
| ⑰ 言語 | 日本語と英語の切り替えができます。 |
| ⑱ テーマ | ライトモードとダークモードの切り替えができます。 |
| ⑲ Microcosmエージェント | Microcosm エージェント一覧を表示します。 |
| ⑳ 画像推論モデル | 画像推論モデル一覧を表示します。 |
| ㉑ 音声読み上げ | 生成した回答を音声で読み上げる機能です。デフォルト設定=Off |
| ㉒ 設問入力フォーム | あなたがAIに投げかける個別の質問や指示(ユーザープロンプト)の入力欄です。(例)『このテキストを要約して』や『この文章を英訳して』設定画面で登録されたシステムプロンプトの振る舞いで、当フォームで入力された設問に対してAIが回答を生成します。 |
| ㉓ スレッド設定 | スレッド毎にモデルやプロンプト等の設定を変更できます。デフォルトでは、設定画面で設定した内容が反映されます。 |
| ㉔ OCR機能 | オフラインOCRのアップロード画面に遷移します。 |
| ㉕ 画像推論 | ファイル選択画面に遷移します。 |
| ㉖ 送信ボタン | 設問をAIにリクエストして回答を得ます。 |
【㉓ スレッド設定画面】


| ㉗ 新規スレッドボタン | 新しいスレッドを作ります。 |
| ㉘ 過去スレッド一覧 | 過去のスレッドが表示されます。スレッドをクリックすると過去のスレッドが表示されます。 |
| ㉙ タイトル編集 | 選択した過去スレッドのタイトルを編集できます。 |
| ㉚ 履歴削除 | 選択した過去スレッド内の会話履歴を削除します。 |
| ㉛ スレッド削除 | 選択した過去スレッドをスレッドごと削除します。 |
| ㉜ スレッド内OCR結果の削除 | 読み込んだOCR結果が削除されます。 |
| ㉝ 設定確認 | スレッド内の回答毎の一部の設定内容を確認できます。 |
| ㉞ コピー | ユーザーの設問、AIの生成した回答テキストをコピーすることができます。 |
| ㉟ 参照情報 | ナレッジビュー機能を利用して回答を生成した場合は、どの部分やファイルを参照したのかを確認することができます。 |
2-2. 設定画面
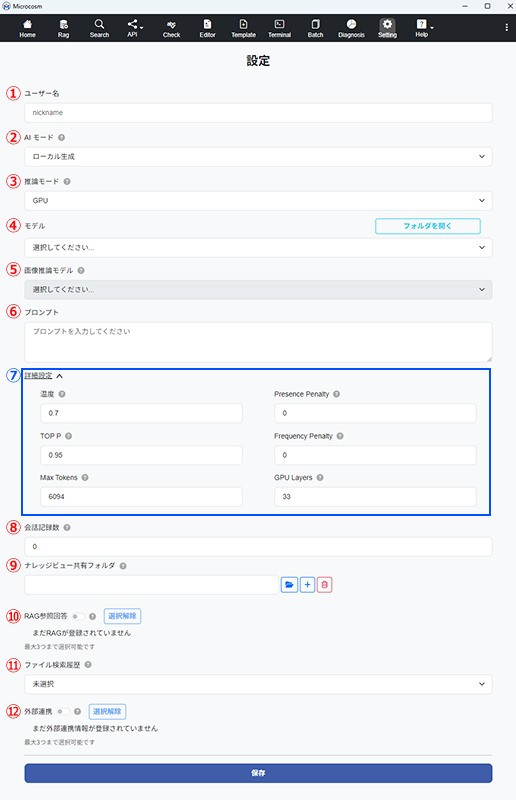
| ① ユーザー名 | ユーザー名です。AIがユーザー名で回答するように今後実装予定です。 |
| ② AIモード | 詳細は2-10. AIモード選択で確認いただけます。 ローカル生成:各クライアントPCで稼働します。 Open AI API:Open AI に連携する機能です。※インターネット接続が必要 Open AI 互換 API:独自サーバ上で稼働させているMicrocosmアプリに各クライアントPCから接続するための機能です。 |
| ③ 推論モード | CPUを選択するとCPUでAIの回答をします。GPUを選択した場合は、GPUでAIの回答をします。 ※現在、NVIDIAのGPUのみ動作検証しております。NVIDIAの場合は当アプリをご利用いただくためにCUDA ツールキットのインストールが必須となります。 以下URLリンクからダウンロード、インストールをお願いします。 CUDA Toolkit 12.6 Update 2 Downloads | NVIDIA Developer |
| ④ モデル | テキストの入力を受け取り、出力テキストを生成するモデルを選択します。モデル一覧画面から追加削除ができます。 |
| ⑤ 画像推論モデル | 画像推論に使用するモデルを選択します。 |
| ⑥ プロンプト | 各会話スレッドにて初期設定されるシステムプロンプトになります。AIが全般的にどんなトーンやスタイルで応答するか、あらかじめベースラインを決めるプロンプトです。(例)『常に丁寧な口調で答えて』や『出力は箇条書きで簡潔に』」 |
| ⑦ 詳細設定 | 温度:0〜2の間で設定します。 temperature(温度)が高いほど、多様で予測しにくい出力が生成されます。逆にtemperatureが低いほど、より確定的で予測可能な出力になります。 TOP P:0〜1の間で設定します。 回答を生成するときに、どれだけ多様な選択肢を考慮するかを決める設定です。数値が低いと、回答が決まったパターンに絞られ、高いとさまざまな候補から選ばれます。 Max Tokens:100〜128000の間で設定します。 生成される回答の最大「単語数」に近い数値です。数が大きいほど長い回答を作れますが、メモリの負荷が増え、処理が遅くなることがあります。 Frequency Penalty:0〜1の間で設定します。 同じ単語や表現を頻繁に使わないよう調整できます。テキスト生成で同じ単語の重複を防ぎたい(多様性や創造性を重視したい)場合は、値を高めに設定してください。 Presence Penalty:0〜1の間で設定します。 回答に1度でも含んだことのある単語を再使用しない率を設定できます。テキスト生成で同じ単語の重複を防ぎたい(多様性や創造性を重視したい)場合は、値を高めに設定してください。 Context Size:128〜128000の間で設定します。 AIに入力できる文章の長さの上限です。大きな値にすると多くの情報を参考にできますが、メモリの関係で処理が遅くなる場合があります。当アプリでは、過去の会話履歴もこの長さに含まれます。 GPU Layers:1〜100の間で設定します。 GPU(高速な計算を行う装置)で処理する「層(レイヤー)」の数を設定する項目です。モデルのサイズに応じて最適なレイヤー数が異なり、例えば7Bモデルなら最大32層、70Bモデルなら最大80層が目安となります。 |
| ⑧ 会話記録数 | スレッド内の会話履歴をいくつまで含めて回答するかを、0〜10の間で設定します。 例)設定を「2」にすると、2つ前までの会話を考慮した回答を生成します。Context Sizeが上限を超えると回答生成に失敗するため、ご注意ください。 |
| ⑨ ナレッジビュー共有フォルダ | ナレッジビューが利用するキャッシュデータを、ファイルサーバー上で他のユーザーと共有するためのフォルダです。 ファイルサーバー環境を使用しない場合は、この設定を変更する必要はないです。 利用環境で指定するフォルダを事前に操作ユーザーへ共有しておく必要があります。 PC上にあるローカルストレージは選択できません。 1ファイルサーバーにつき、1フォルダのみ選択できます。 ナレッジビューを使用するユーザーが書き込み権限を持つフォルダである必要があります。 |
| ⑩ RAG参照回答 | ONにすると、指定したRAGデータを参考に回答が生成されます。OFFの場合、RAGデータを検索しません。RAGデータは最大3つまで選択可能です。 |
| ⑪ ファイル検索履歴 | ファイル検索履歴から選択したファイル内データを取得して回答が生成されます。ファイルデータは最大3つまで選択可能です。 |
| ⑫ 外部連携 | ONにすると、指定した外部連携APIからデータを取得して回答が生成されます。OFFの場合、外部連携APIからデータを取得しません。外部連携APIは最大3つまで選択可能です。 |
2-3. RAG一覧画面
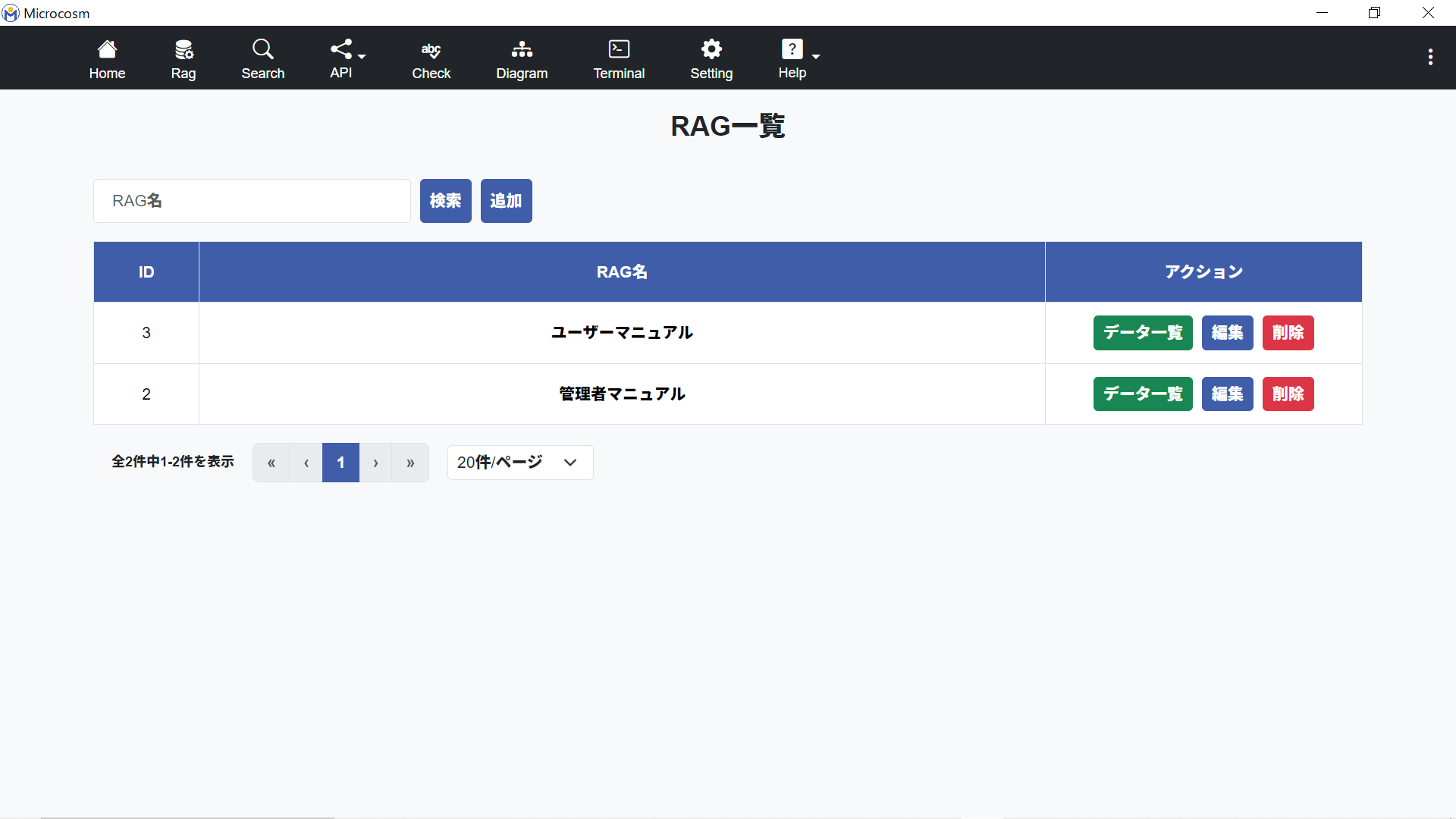
 | 指定したRAG名で検索します。 |
 | RAG登録画面に遷移します。 |
 | RAGデータ一覧画面に遷移します。 |
 | RAG名を編集します。 |
 | RAGを削除します。 |
2-3-1. RAGデータ一覧画面
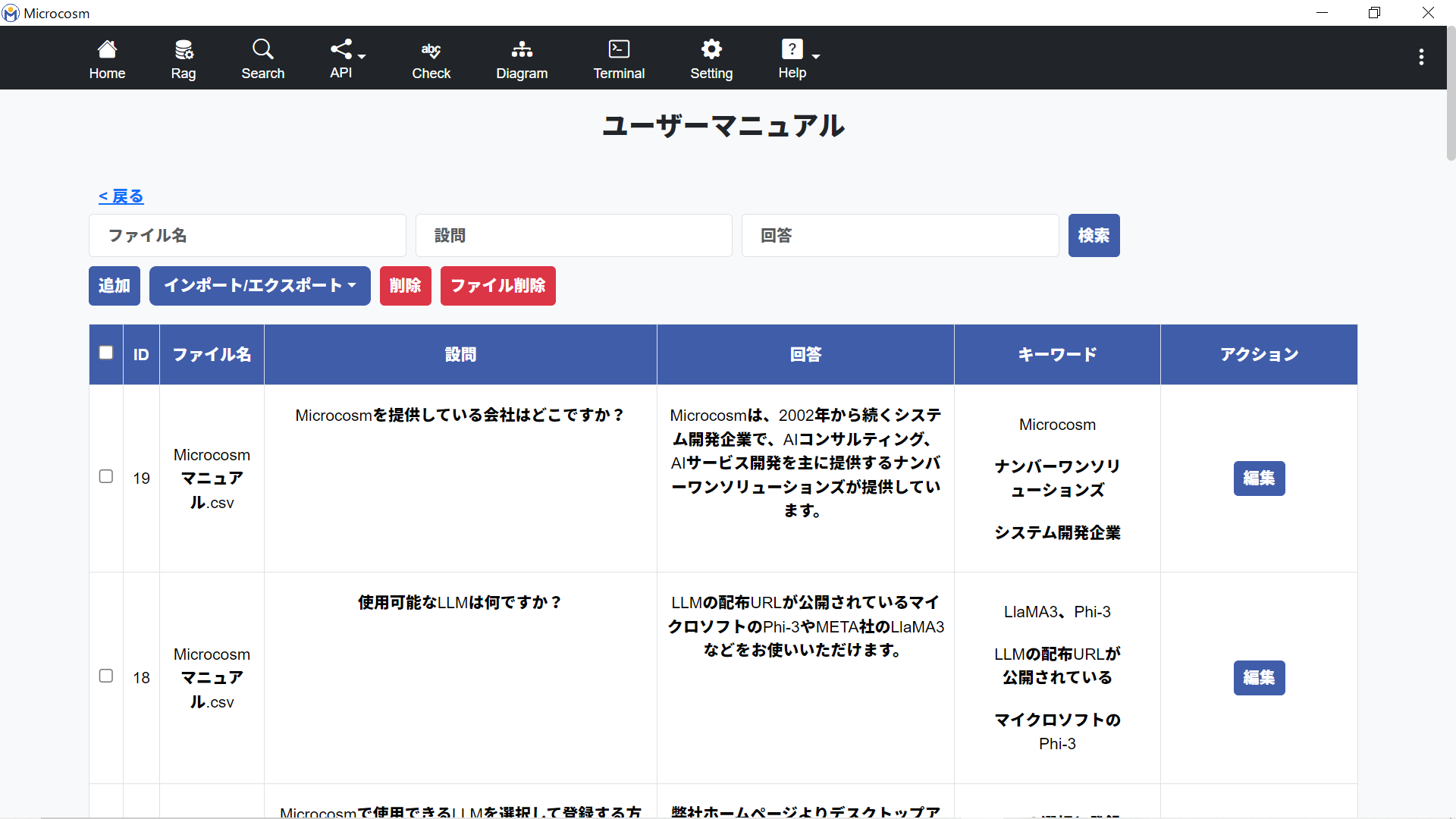
| RAGデータ一覧内の対象データを検索して表示します。 |
| RAGデータ登録画面に遷移します。 |
 | RAGインポート/CSVインポート:各画面に遷移します。 CSVエクスポート:エクスプローラーが起動します。 |
| 選択したRAGデータを削除します。 |
 | 指定したファイル名で生成されたRAGデータを一括削除します。 |
| RAGデータの内容を編集します。 |
2-3-2. RAGインポート画面
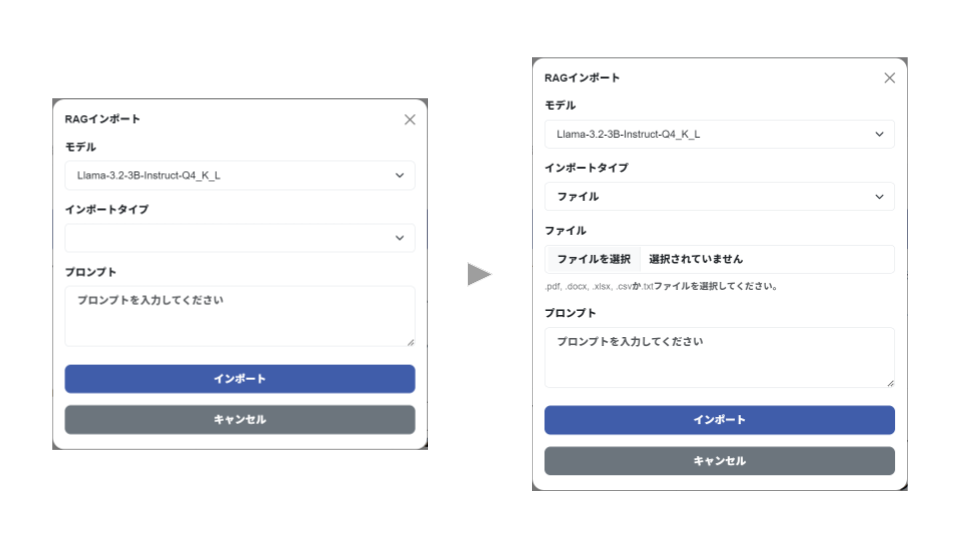
| モデル | インポートデータをもとにRAGデータ作成に使用するモデルを選択します。 |
| インポートタイプ | 下記の2パターンから選択します。 ファイル:指定したファイルでインポートをする ディレクトリ:指定したディレクトリ配下のファイルで該当する拡張子の全ファイルをインポートをする |
| プロンプト | RAGデータ作成時に考慮してもらいたい指示を任意で設定します。 |
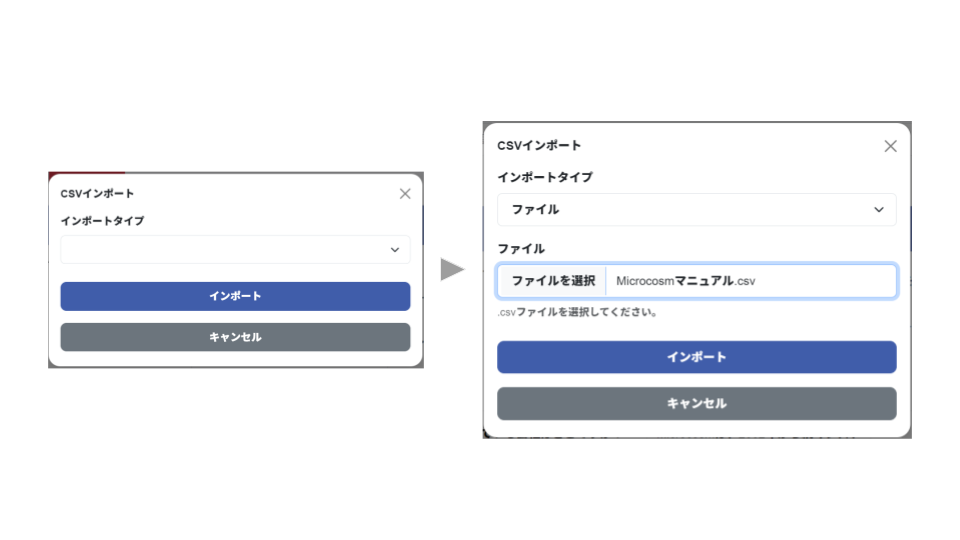
2-3-3. CSVインポート画面
AIを使用せずに、CSVファイルをインポートします。
2-3-4. RAG/RAGデータ作成手順
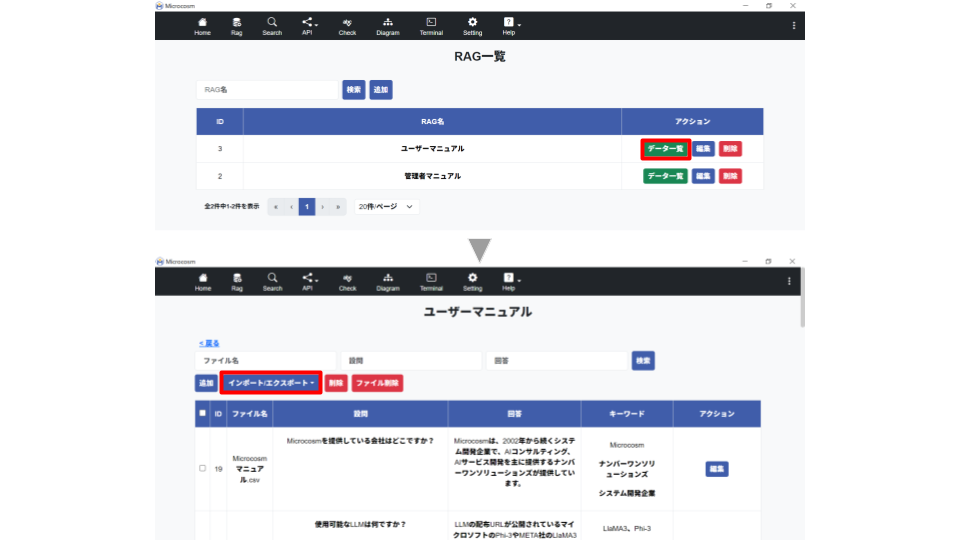
① RAG一覧画面より、
② 作成したRAG一覧画面に表示されている
③ (⑤へ)をクリック
④(
設問と回答を入力し
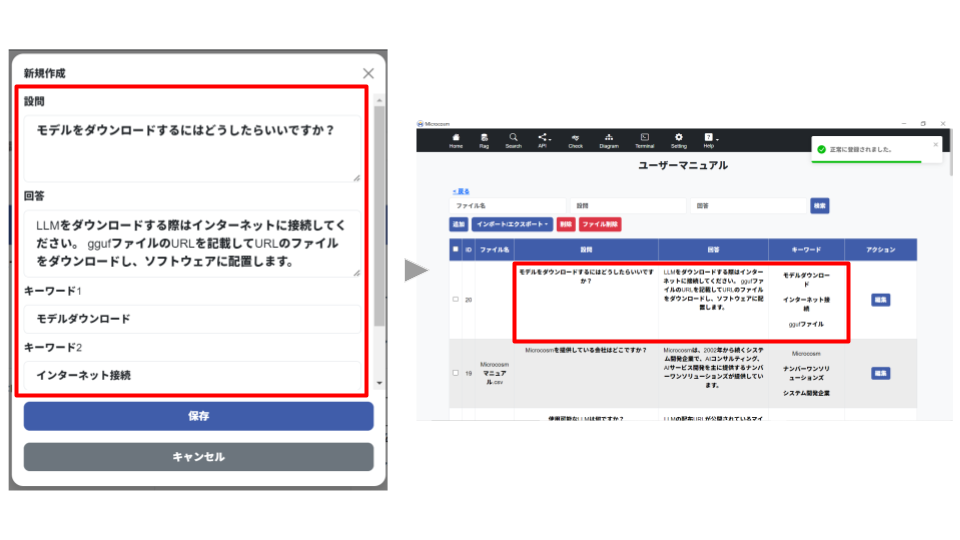
⑤(の場合の手順)
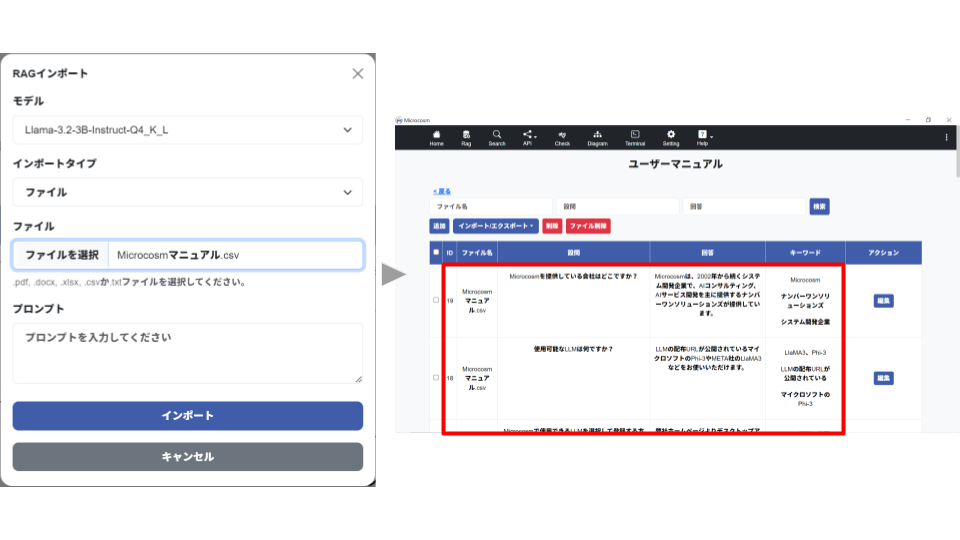
▼RAGインポート
RAGデータ作成用の「モデル」と、「インポートタイプ」をそれぞれ選択します。
「プロンプト」には、RAGデータ作成時に考慮する指示を任意で設定します。
【資料内のテキスト情報をチャンク分割してからRAGデータを作りたい場合のプロンプト例】
#指示
以下の制約条件と添付資料をもとに、論理的なチャンクに分割した上でQAペアを生成してください。
#手順
1. 文書を主要なトピックごとに分割
2. 各チャンクから重要な情報を抽出
3. 各チャンクにつき3-5個のQAペアを生成
#制約条件
・各チャンクは独立して理解可能な単位にする
・チャンク間の重複を最小限に
・生成するQAは以下の基準を満たすこと:
・明確な質問
・正確な回答
・チャンクの主要な情報を網羅
・単一の概念に焦点
# 出力フォーマット
[チャンク 1]
Q: [質問1]
A: [回答1]
Q: [質問2]
A: [回答2]
▼CSVインポート
デバイス内のCSVファイルをインポートする機能です。
CSVファイル内のデータをそのままMicrocosmに取り込みます。

▼CSVエクスポート
RAGに登録しているデータをCSVでエクスポートする機能です。
RAGデータを外部に共有したい時に使用します。
2-4. 【製品版限定】AIファイル検索機能

| モデル | 検索に使用するモデルを選択します。 |
 | 検索したいデバイス内のディレクトリを参照します。 |
| 検索する対象ファイル | 検索したいファイルのファイル形式を選択します。 |
| 要約のみ抽出 | 検索したいファイルの要約のみを抽出したい場合、チェックを入れます。 |
| ファイルコンテンツの利用範囲 | どこまでファイルの内容を使うかを選びます。 部分抽出:必要なところだけ使う方法で、出力の精度が上がることがあります。 全文使用:すべてのコンテンツを使う方法で、高性能なAIを使う場合に適しています。 |
| プロンプト | 検索したいファイルについて指示をします。 |
 | 検索を実行します。 |
 | ①~④で設定した内容をすべてクリアします。 |
 | 検索履歴を表示します。 |
2-4-1. AIファイル検索手順
① 「モデル」を選択
②
③ 「検索対象ファイル」より、任意のファイル形式を選択
④「プロンプト」に「〇〇についての資料を探して」等の指示を入力し、をクリック
検索が完了すると、同画面下に以下のような結果が出ます。
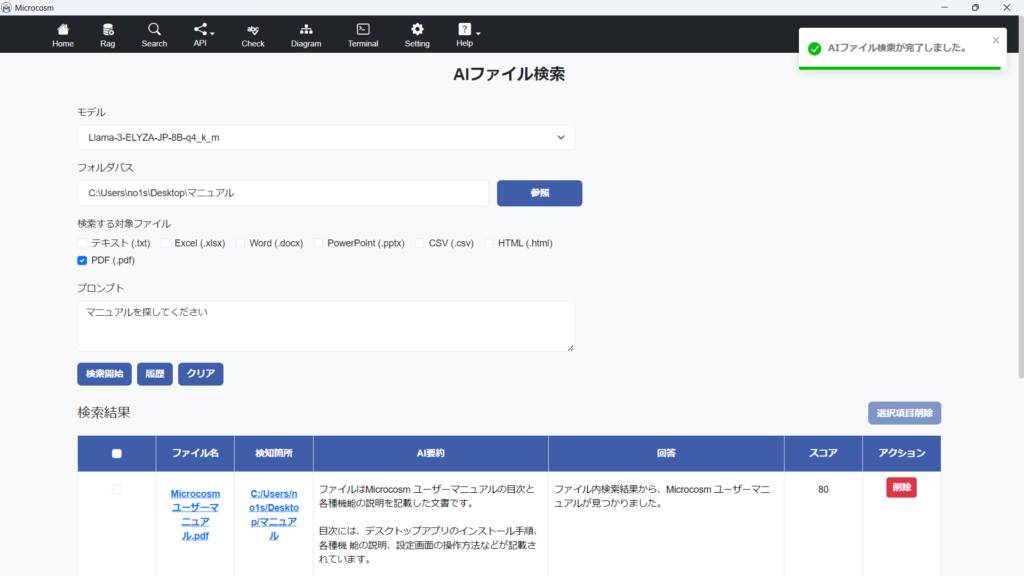
2-4-2. AIファイル検索履歴画面
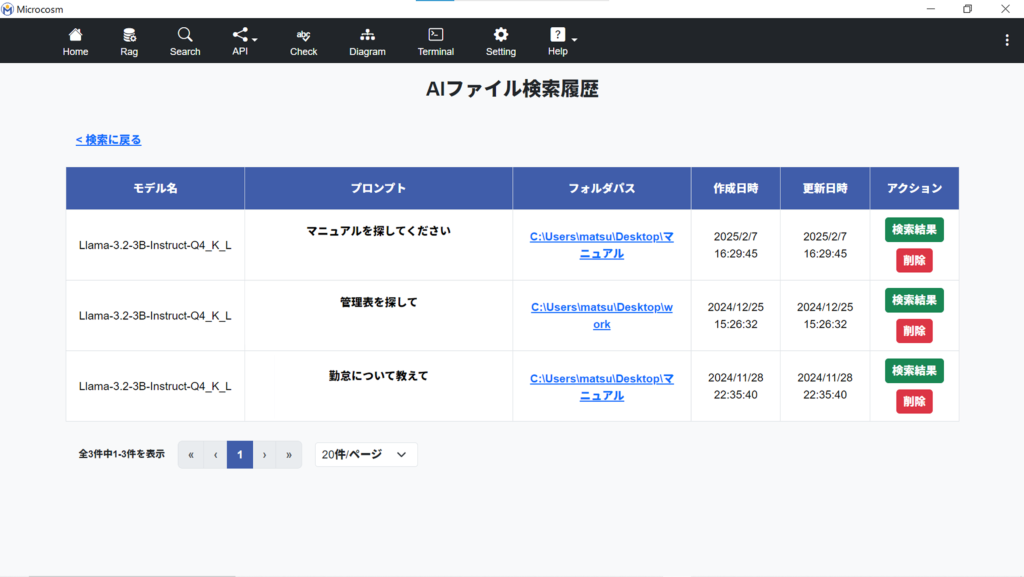
 | 検索結果の詳細は、下記の(2-4-3)画面へ遷移します。 |
| 検索結果を履歴から削除します。 |
2-4-3. 検索結果画面
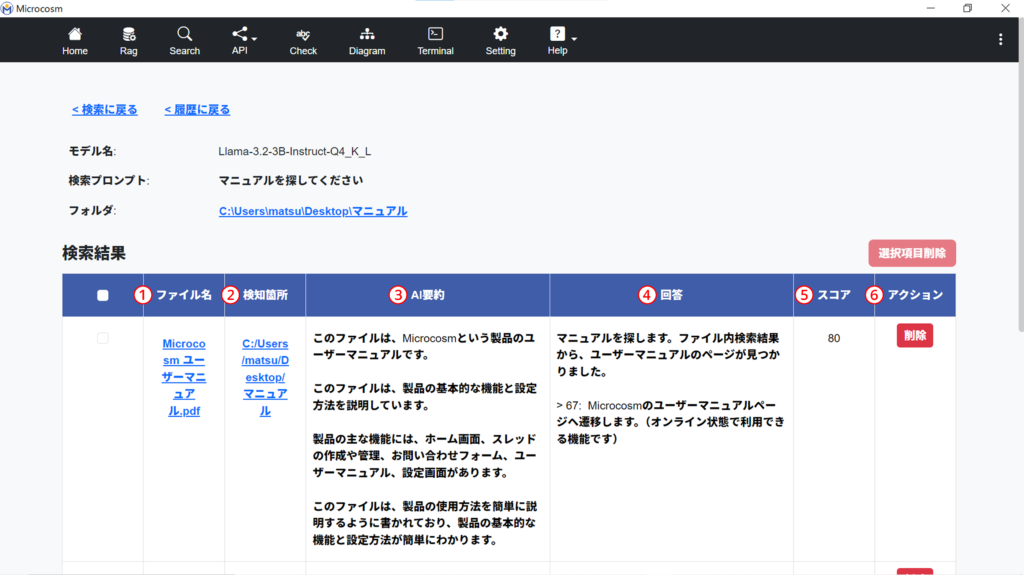
| ① ファイル名 | 検索したファイル名 |
| ② 検知箇所 | ファイルが存在しているディレクトリパス |
| ③ AI要約 | AIが要約したファイルの内容です。 |
| ④ 回答 | ①の検索プロンプト内容に対する、AIの回答です。 |
| ⑤ スコア | 複数あるファイルの中から、AIの判断で一致率の高い順に表示します。 |
| ⑥ アクション | ファイルを削除します。 |
 | 検索結果をチェックボックスで選択し、一覧から削除します。 |
検索したファイルの内容についてAIに質問したい場合は、設定画面に遷移し、ファイル検索履歴から該当するファイルを選択して登録します。

2-5.【製品版限定】外部連携一覧画面
外部のAPIエンドポイントに対して任意のリクエスト(GET/POSTなど)を行い、そのレスポンスをMicrocosmに取り込む機能です。
外部連携機能によって、さまざまな公開API(官公庁オープンデータ、地域イベント情報、料理レシピ検索、天気や交通、金融、ニュース、地図・位置情報サービスなど)から、認証・パラメータ設定を行い、任意の情報を取得してMicrocosmと連携することが可能になります。
【公開API一例】
官公庁オープンデータ/地域イベント情報/料理レシピ検索/天気/交通/金融/ニュース/地図/位置情報サービスなど

| 指定したAPI名で検索します。 |
| API登録画面に遷移します。 |
| API名を編集します。 |
| APIを削除します。 |
2-5-1. 外部連携登録方法
たとえば、ランダムな犬の画像URLを取得するAPIを設定してみます。
API名:Dog CEO’s Dog API
エンドポイントURL:https://dog.ceo/api/breeds/image/random
※このAPIにGETリクエストを送信すると、ランダムな犬の画像URLがJSON形式で返されます。
メソッド:GET

登録ボタン押下前にAPI実行ボタンを押下し、200とレスポンス内容が正常であることを確認します。※認証がある場合も同様に認証実行ボタンを押下し、正常であることを確認します。

正常に作動することを確認したら登録ボタンを押下し、外部連携APIの登録が完了します。

登録後、設定画面またはホームのスレッド内で、使用する外部連携APIを選択して設定を保存します。

ホーム画面で会話を開始すると、APIの結果を踏まえて回答が生成されます。

2-6.【製品版限定】誤字脱字チェック機能
AIモデルに資料を読み込ませ、誤字脱字箇所を確認・修正する機能です。

| モデル | 誤字脱字チェックに使用するモデルを選択します。 |
| 誤字脱字チェックをしたいデバイス内のファイルを参照します。 |
 | 誤字脱字チェックを実行します。 |
2-6-1. 誤字脱字チェック方法
誤字脱字を確認及び修正する際に使用する「モデル」を選択し、
「プロンプト」に確認内容または修正内容の指示を入力し、
※空欄でも実行可能です。
処理が完了すると、以下の通り結果が表示されます。

 | 指定したファイルの拡張子と同じファイルで修正したファイルを出力することができます。 |
 | 誤字脱字修正後のPDFファイルを出力することができます。※ファイル内に画像やグラフがある場合、ファイル出力に失敗する場合があります。 |
2-7. モデル一覧画面
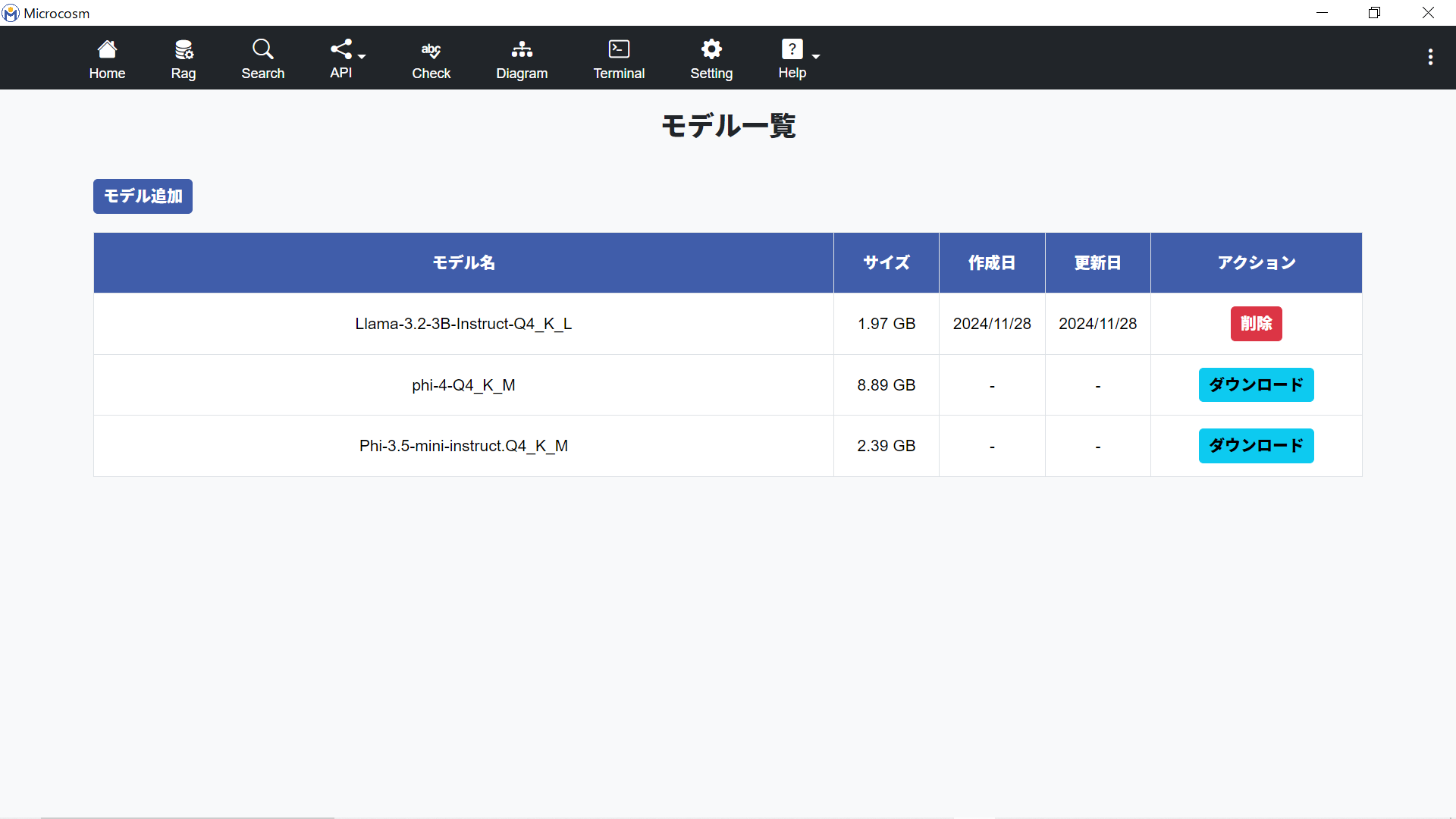
 | モデル追加画面に遷移します。 |
| モデルを削除します。 |
 | デフォルトのモデルをダウンロードします。※使用のためには、インターネット接続が必要です(アプリ内の情報が漏洩することはありません)。 |
2-7-1. モデル追加画面
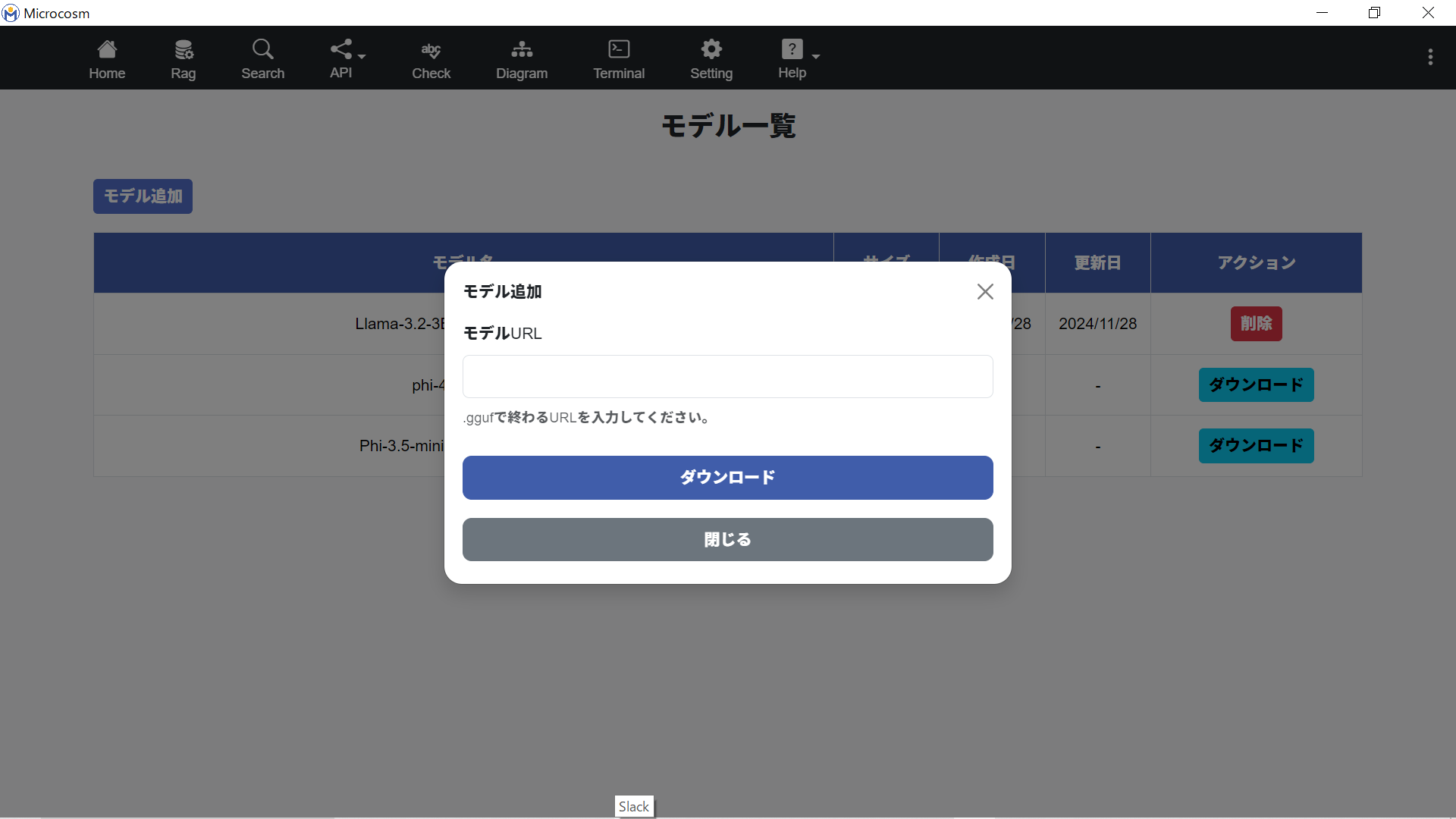
| モデルURL | ggufファイルのURLを記載してURLのファイルをダウンロードします。 |
2-7-2. モデル追加方法
モデル一覧画面内の
モデル追加画面内の「モデルURL」フィールドに”.gguf”※で終わるURLを入力し、ダウンロードボタンをクリックします。LLMをダウンロードする際はインターネットに接続してください。
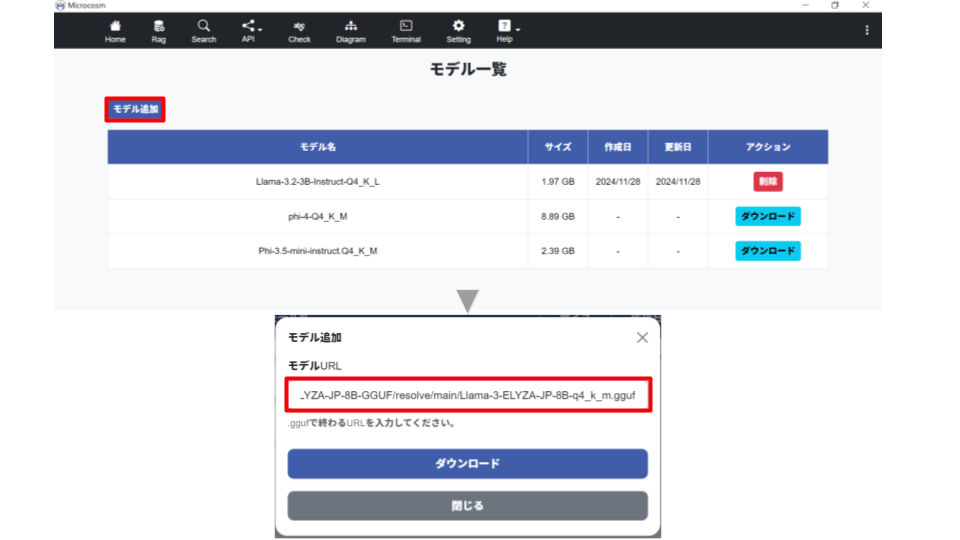
【ダウンロードするURL例】
https://huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q4_K_L.gguf
※ モデルの配置場所は、以下となります。直接配置してもモデルを読み取ります。
C:\Users\{ユーザー}\AppData\Roaming\microcosm\models
{ユーザー}はPCにログイン中のアカウント情報に置き換えてください。
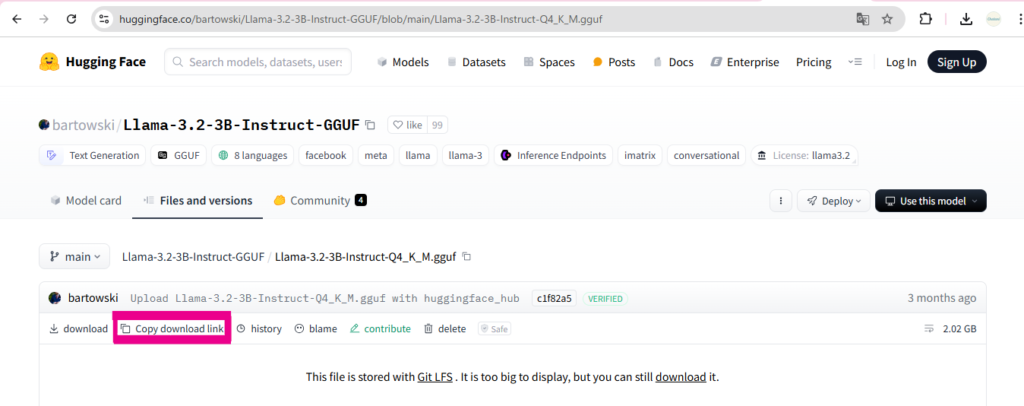
※AI開発プラットフォーム「Hugging Face」等からURLを取得される場合は、下記画像赤枠の”Copy download link”からコピーしてください。アドレスバーのURLはモデルのダウンロードにご使用いただけないため、ご注意ください。
2-8.【製品版限定】音声読み上げ機能
AIが生成する回答を音声で読み上げる設定をします。デフォルトでは「OFF」になっています。
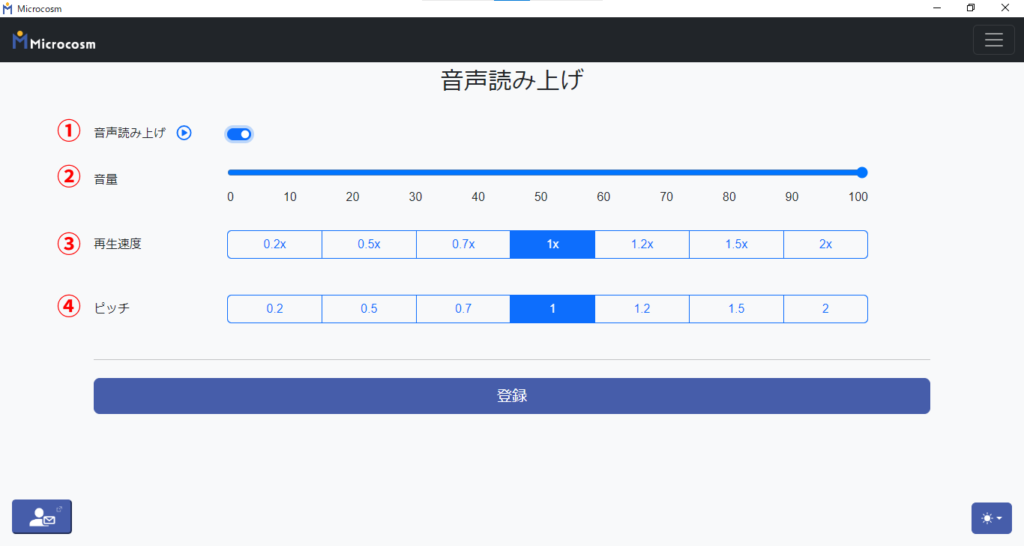
| ① 音声読み上げ | 読み上げ機能のON/OFFを切り替えます。 をクリックすると、現在の設定内容でサンプル音声を再生します。 をクリックすると、現在の設定内容でサンプル音声を再生します。 |
| ② 音量 | 読み上げ機能の音量を設定します。 |
| ③ 再生速度 | 読み上げ速度を設定します。 |
| ④ ピッチ | 読み上げ音声の高さを設定します。数が小さいほど低く、大きいほど高くなります。 |
2-9. AIモード選択
▼Open AI API連携
インターネットに接続して使用する機能です。

【事前準備】
OpenAIのサイトより、APIキーを取得してください。
OpenAI公式サイト:https://openai.com/ja-JP/api/
【設定手順】
① 設定画面より、「AIモード」で「Open AI API」を選択
②を押し、事前に取得したOpenAIの「APIキー」入力して保存
③ 任意のgptモデルを選択してを押し、設定完了

▼Open AI 互換 API連携
内部ネットワークに接続してMicrocosmを使用する機能です。

【事前準備】
☑ワークステーションの環境設定(別途)
☑ワークステーションより、エンドポイントとAPIキーを取得してください。
【設定手順】
① 設定画面より、「AIモード」で「Open AI 概要 API」を選択
② 各を押し、事前に取得した内部ネットワークの「エンドポイント」と「APIキー」入力して保存
③ ワークステーション内に設定した、任意のモデルを追加・選択して、設定完了
3. アプリの初期化方法
Microcosmアプリ自体をアンインストールした場合でも、履歴やモデル等のデータはローカル環境内に残っています。そのためMicrocosmで使用したデータを完全に初期化したい場合は、以下の手順を実施してください。
① アプリを終了する
② エクスプローラ上部に以下パスを入力し、Roamingフォルダを開く
C:\Users\{ユーザー}\AppData\Roaming
※{ユーザー}はPCにログイン中のアカウント情報に置き換えてください。
③ microcosmフォルダごと削除する
④ 実行ファイルを再度インストールする
4. 追加実装機能(2025/04~アップデート)
4-1. エディター機能画面(基本機能)
ダイアグラムやドキュメントをAIで作成したり、データを編集/エクスポートできる機能です。

| ① ファイル作成 | ファイルを新規作成します。 |
| ② フォルダ作成 | フォルダを新規作成します。 |
| ③ リフレッシュ | デバイス内のフォルダにファイル/フォルダを直接作成した場合に使用します。作成されたファイル/フォルダがファイルツリーに表示されます。 |
| ④ 削除 | 選択したファイル/フォルダを削除します。 |
| ⑤ 検索 | ファイルツリー内のファイル/フォルダを各名称で検索します。 |
4-1-1. ファイル作成画面

| 作業内容 | 文章:ドキュメントやグラフを作成するエディター機能です。 図 :フロー図やチャート図などを作成するダイアグラム機能です。 |
| ファイル形式 | 「Markdown」または「JSON」のみ選択可能です。 |
| ファイル名 | 任意のファイル名を登録します。 |
4-1-2. フォルダ作成画面
| フォルダ名 | 任意のフォルダ名を登録します。 |
4-1-3. 共通画面
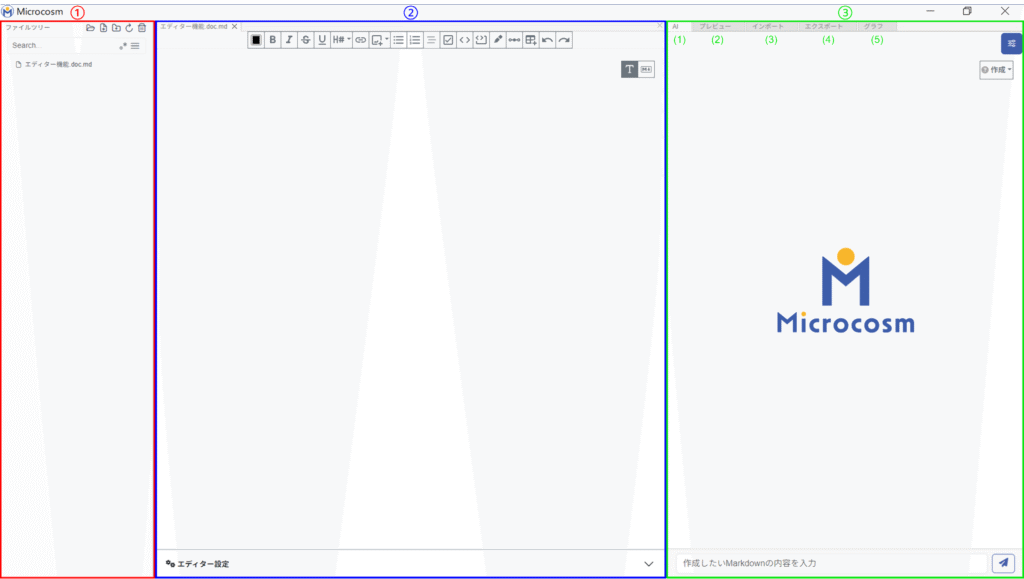
| ① ファイルツリー | 作成したフォルダ内のファイルやフォルダが並びます。 |
| ② データ編集画面 | 選択したファイルのデータを編集します。 |
| ③ 右サイドパネル画面 | (1)AI:チャット形式で文章や表のアイディアをAIが作成します。 (2)プレビュー:データ編集画面で編集した内容の、プレビュー表示ができます。※ (3)インポート:モデルとファイルパスを選択し、既存ファイルをインポートすることができます。 (4)エクスポート:編集したファイルを各種形式でエクスポートできます。 (5)グラフ:インポートをしたファイルデータを元にグラフを作成します。 ※Diagram作成時は、「プレビュー」のみになります。 |
4-2. Diagram作成画面
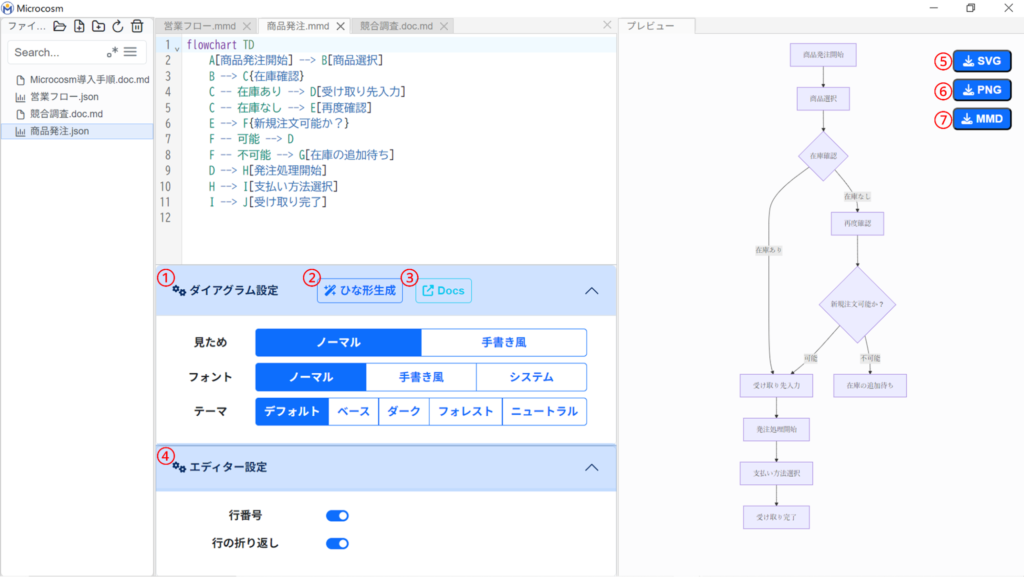
| ① ダイアグラム設定 | ダイアグラムの見ため/フォント/テーマを設定できます。 |
| ② | 新たにひな形を作成します。 |
| ③ | ダイアグラム作成の参考として、Mermaidのドキュメントページ※に遷移します。※外部ネットワークを使用します。 |
| ④ エディター設定 | 「行番号」:データ編集画面内の行番号の設定ができます。 「行の折り返し」:長いテキストデータを折り返し表示できます。 |
| ⑤ | 作成したダイアグラムをSVGファイルでエクスポートします。 |
| ⑥ | 作成したダイアグラムをPNGファイルでエクスポートします。 |
| ⑦ | 作成したダイアグラムをMMDファイルでエクスポートします。 |
4-2-1. Diagram作成手順
ダイアグラムは、ユーザー自身で作成、AIでひな形作成、テンプレートでひな形作成の3つの方法で作図することができます。

① エディター機能の初回起動時、またはCtrl + Shift + Oで、デバイス内にMicrocosmで作成したダイアグラムを保存するフォルダを選択または作成します。
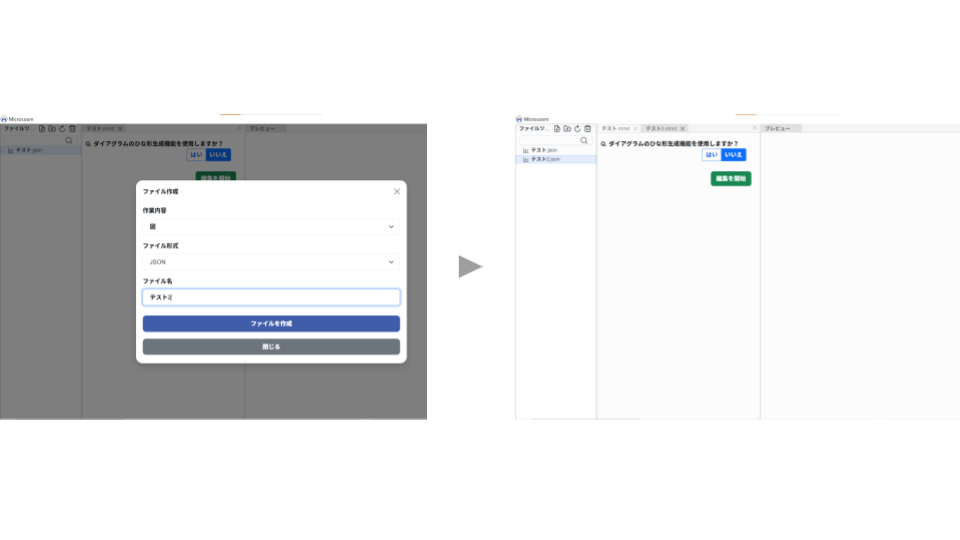
② ファイル作成/フォルダ作成をクリックし、必要事項を入力してファイル/フォルダを作成します。手順①で選択したフォルダ内に、ファイル/フォルダが作成されていきます。
③ 手順②で作成したファイルまたは任意のファイルを選択し、(④へ)または
(⑤/⑦へ)を選択
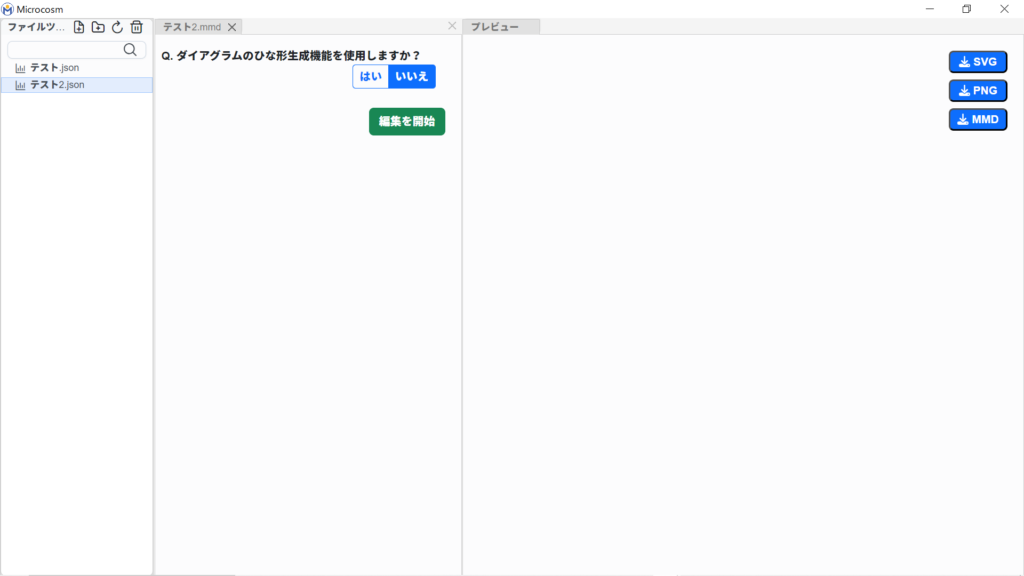
④ を選択した場合
中央部、「データ編集画面」にて、ユーザー自身でダイアグラムを作成※できます。
※マークダウン形式での作成になります。
⑤ を選択し、
を選択した場合
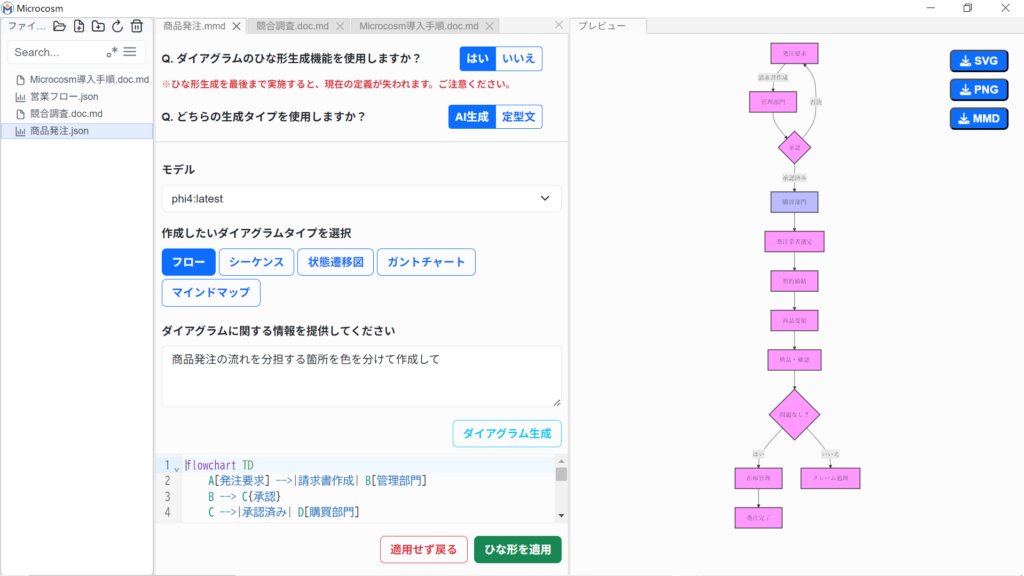
選択した任意のダイアグラムタイプをAIが作成します。
フロー/シーケンス/状態遷移図/ガントチャート/マインドマップの中から選択し、をクリックしてください。
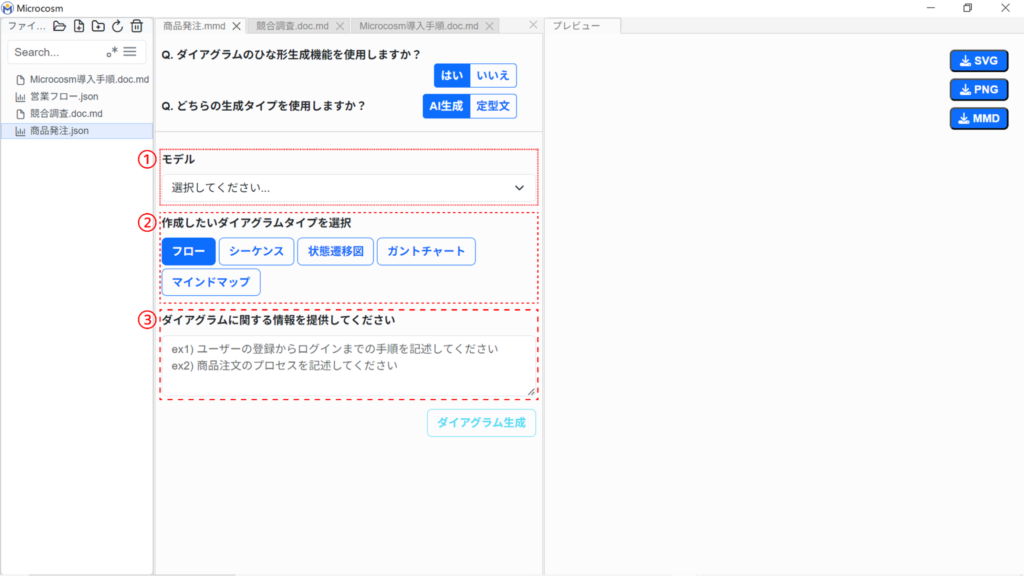
| ① モデル | ダイアグラムを作成するモデルを選択します。 |
| ② ダイアグラムタイプ選択 | フロー/シーケンス/状態遷移図/ガントチャート/マインドマップ |
| ③ プロンプト | どんな内容のダイアグラムを作成したいのかを指示します。 |
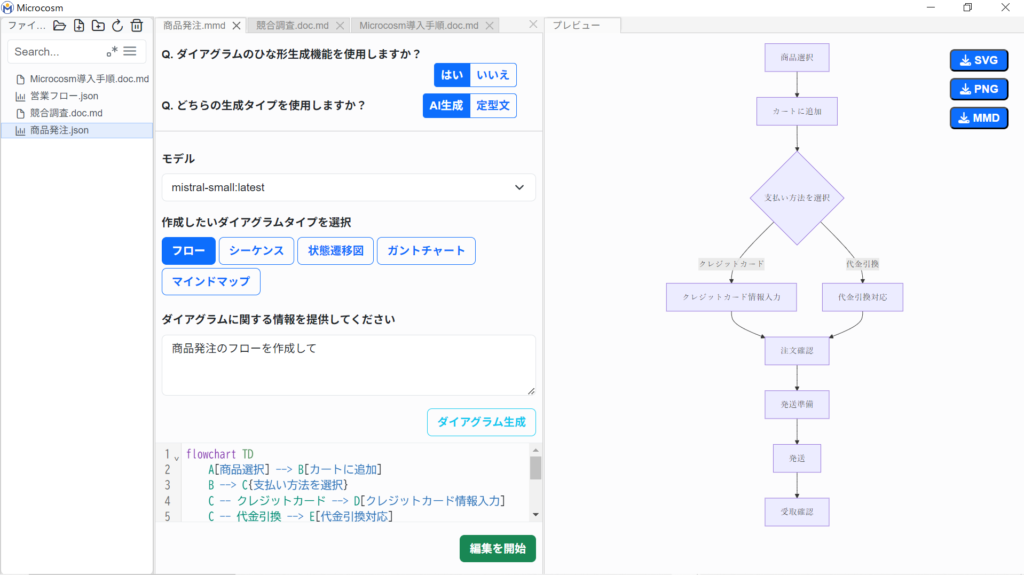
⑥※ 作成後、「プレビュー画面」に作成された図が表示されます。で図を保存することが可能です。
さらに「プロンプト」を編集し、を実行するとAIが図を再作成します。
図のコンテンツは、マークダウン方式で表示され、ユーザー自身で直接編集することも可能です。
※をクリックした場合⑧へ
※この時点でMicrocosmを閉じてしまうと、編集内容が残らないため注意してください。
⑦ を選択し、
を選択した場合
任意のダイアグラムタイプのテンプレートを選択し、自身で編集/作成します。選択した後に、をクリックしてください。
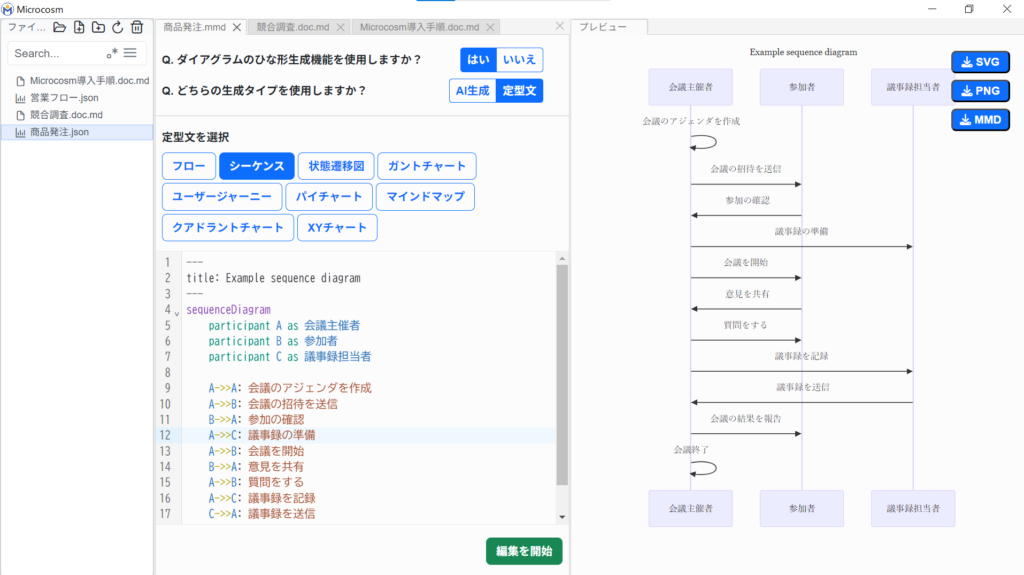
⑧ 図のコンテンツは、中央部、「データ編集画面」にてマークダウン方式で表示され、ユーザー自身で直接編集をします。
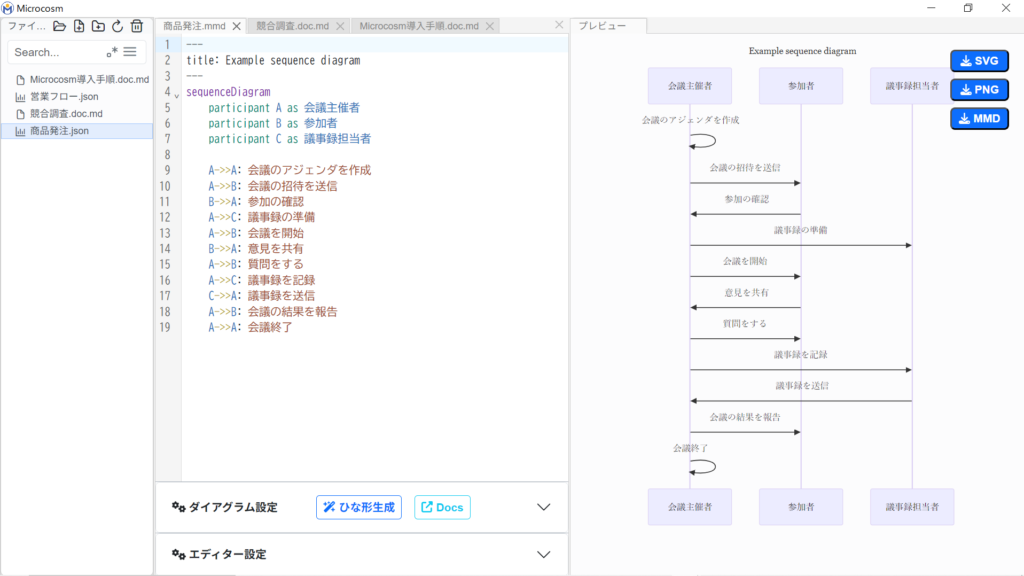
⑨ ![]() を選択した場合
を選択した場合
手順⑤または⑦で作成した図の編集状況を残したまま、新たなひな形を作成できます。を選択してください。(⑩へ)
をクリックすると元の画面に戻ります。
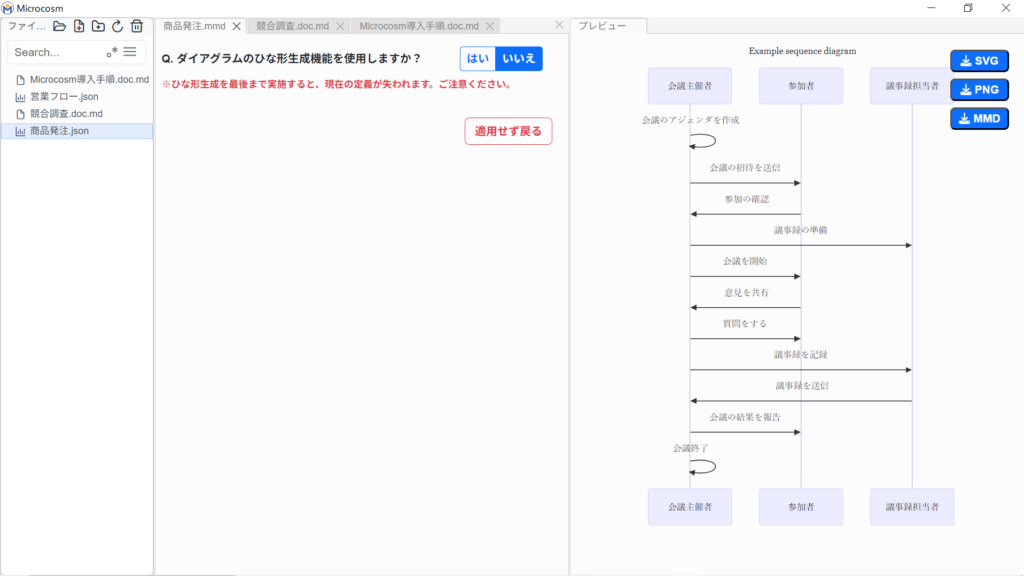
⑩ 作成手順の⑤/⑦と同様の手順で進めます。「データ編集画面」と「プレビュー画面」には、新しく作成する図が表示されます。をクリックすると、手順⑧と同様の画面に遷移します(AI/定型文共通)。
4-3. Document作成画面
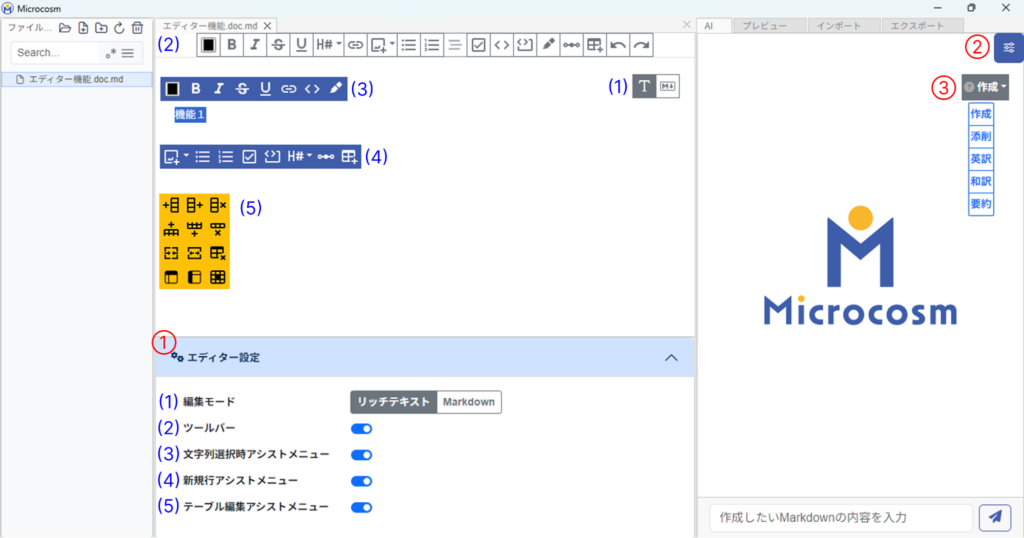
| ① エディター設定※ | (1)編集モード:「リッチテキスト」と「マークダウン」形式を選択できます。 ▼「リッチテキスト」 (2)ツールバー:テキストの色やサイズ設定、画像やリンクの挿入などができます。 (3)文字列選択時アシストメニュー:テキストを選択した際に、一部のツールをアシストメニューとして表示できます。 (4)新規行アシストメニュー:新しく改行した行に対し、一部のツールをアシストメニューとして表示できます。デフォルトは「オフ」です。 (5)テーブル編集アシストメニュー:テーブルを作成した際に、一部のツールをアシストメニューとして表示できます。 ▼「マークダウン」 4-2-1. Diagram作成画面の④と同様。 |
| ② AI詳細設定 | 使用するAIの設定をします。 |
| ③ 推論モード | AIの推論モードを変更できます。 作成: Markdown生成 添削: 指定した行を添削 英訳: 指定した行を英訳 和訳: 指定した行を和訳 要約: 指定した行を要約 |
4-3-1. Document作成手順
ドキュメント作成では、既存ファイルの編集または新たにドキュメントファイルを作成することができます。

① エディター機能の初回起動時、またはCtrl + Shift + Oで、デバイス内にMicrocosmで作成したドキュメントを保存するフォルダを選択または作成します。
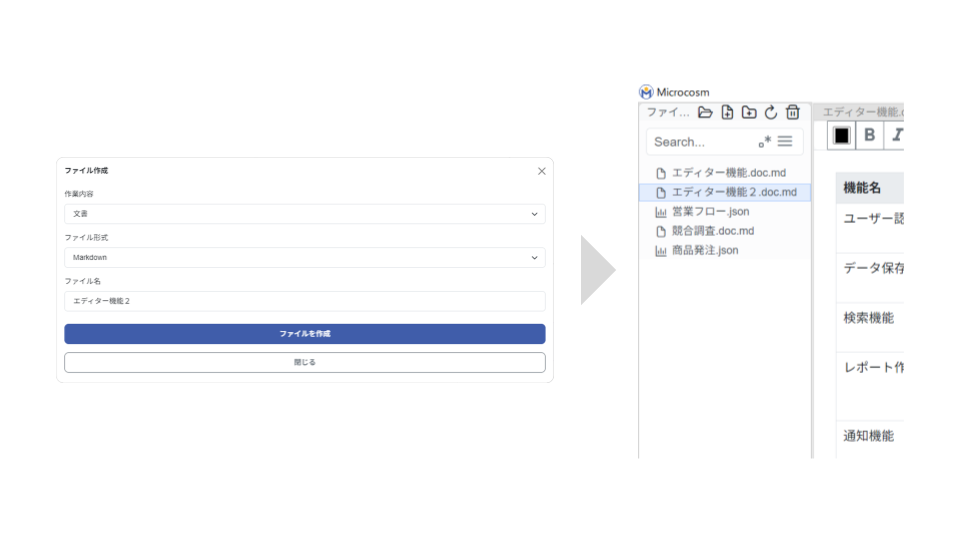
② ファイル作成/フォルダ作成をクリックし、必要事項を入力してファイル/フォルダを作成します。手順①で選択したフォルダ内に、ファイル/フォルダが作成されていきます。
③ 手順②で作成したファイルまたは任意のファイルを選択し、中央部のデータ編集画面でリッチテキストまたはMarkdown形式で編集を行います。
4-3-2. Document作成時の右サイドパネル活用
▼AI
AI詳細設定より、任意の設定をします。
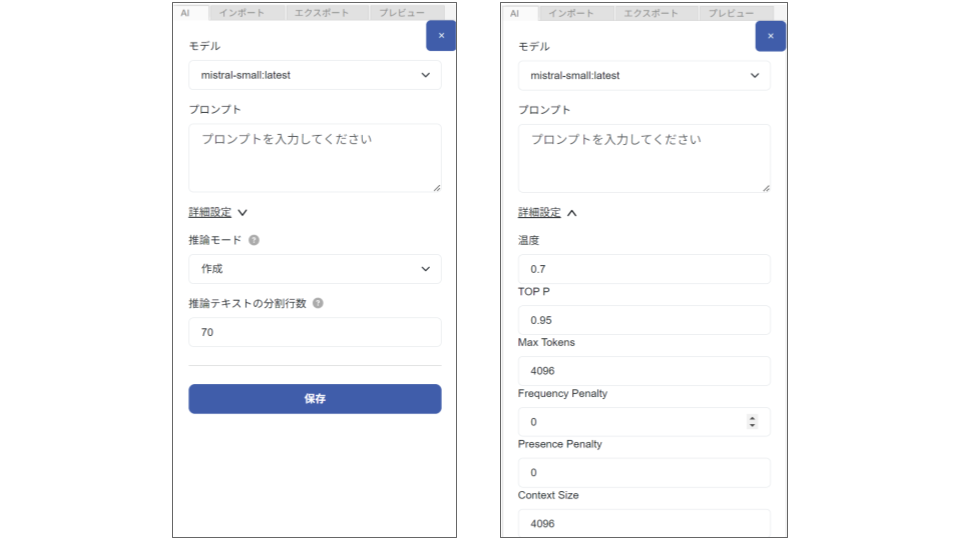
| ① モデル | テキストの入力を受け取り、出力テキストを生成するモデルを選択します。 |
| ② プロンプト | エディター機能でのみ設定されるシステムプロンプトになります。AIが全般的にどんなトーンやスタイルで応答するか、あらかじめベースラインを決めるプロンプトです。入力がなくても使用可能です。(例)『常に丁寧な口調で答えて』や『出力は箇条書きで簡潔に』」 |
| ③ 詳細設定 | 温度:0〜2の間で設定します。temperature(温度)が高いほど、多様で予測しにくい出力が生成されます。逆にtemperatureが低いほど、より確定的で予測可能な出力になります。 TOP P:0〜1の間で設定します。回答を生成するときに、どれだけ多様な選択肢を考慮するかを決める設定です。数値が低いと、回答が決まったパターンに絞られ、高いとさまざまな候補から選ばれます。 Max Tokens:100〜128000の間で設定します。生成される回答の最大「単語数」に近い数値です。数が大きいほど長い回答を作れますが、メモリの負荷が増え、処理が遅くなることがあります。 Frequency Penalty:0〜1の間で設定します。同じ単語や表現を頻繁に使わないよう調整できます。テキスト生成で同じ単語の重複を防ぎたい(多様性や創造性を重視したい)場合は、値を高めに設定してください。 Presence Penalty:0〜1の間で設定します。回答に1度でも含んだことのある単語を再使用しない率を設定できます。テキスト生成で同じ単語の重複を防ぎたい(多様性や創造性を重視したい)場合は、値を高めに設定してください。 |
| ④ 推論モード | AIの推論モードを変更できます。 |
| ⑤ 推論テキストの分割行数 | 推論対象のテキストが多い場合、指定した行数ごとに分割して推論を行います。デフォルトは70行です。使用するモデルによって精度が変わるため、適切な行数を設定してください。 |
【AI使用手順】
① 右サイドパネル画面の「AI」タブを選択し、テキスト入力をして送信をします。
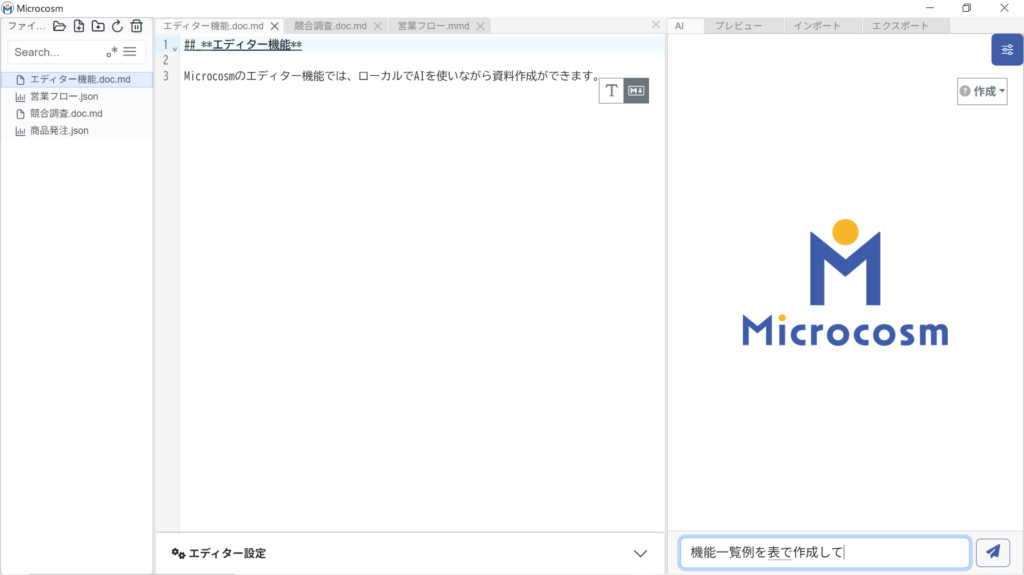
② AIが作成したテキスト等は、マークダウン形式で作成されます。を選択して、Markdownの任意の行へCtrl+Vで貼り付けてください。
※反映に少々時間がかかる可能性があります。そのため、貼り付け後は1秒ほど時間をおいてから次の操作を行ってください。
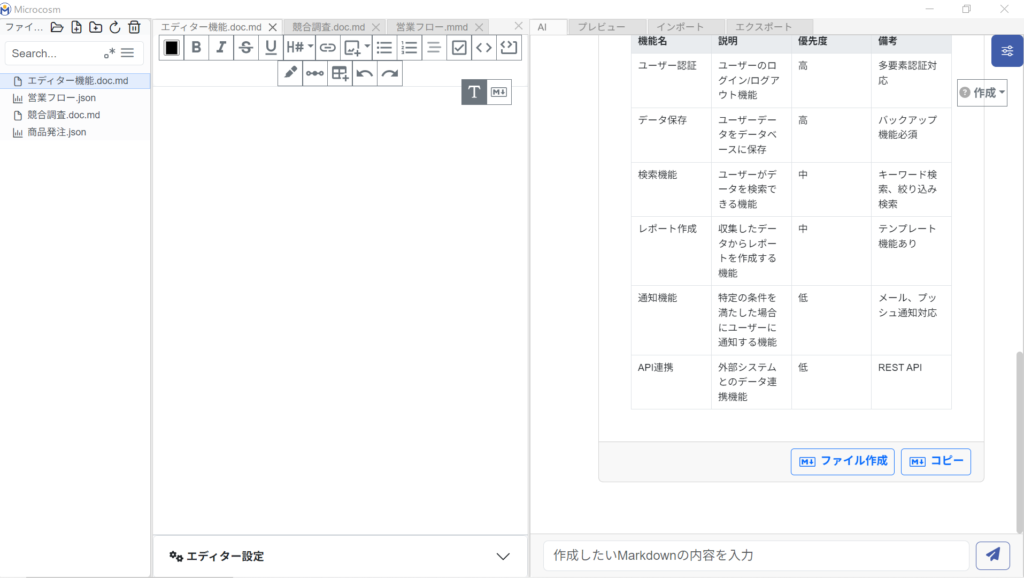
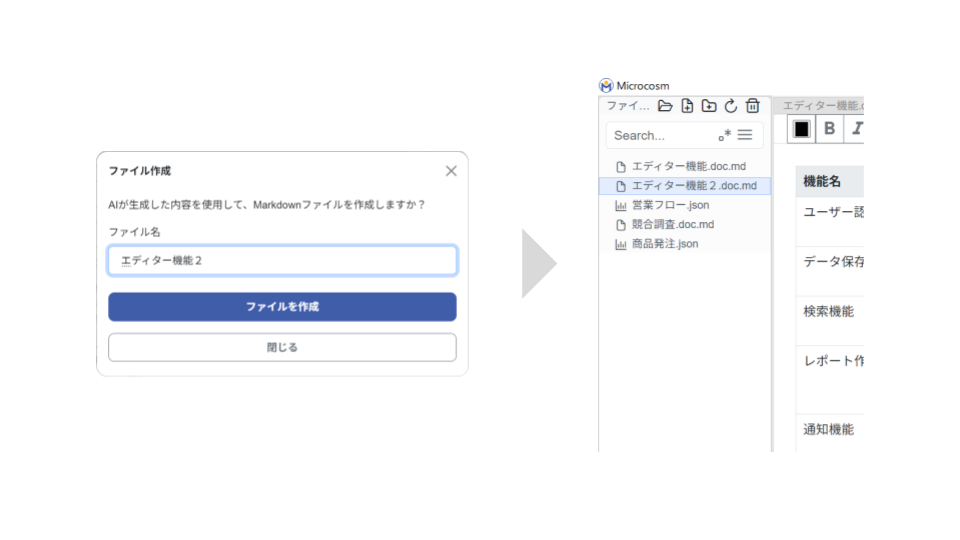
③ AIが生成したテキスト等を別ファイルとして作成する場合は、を選択してください。④ 任意のファイル名を入力し、
を押すとファイルツリーに追加されます。
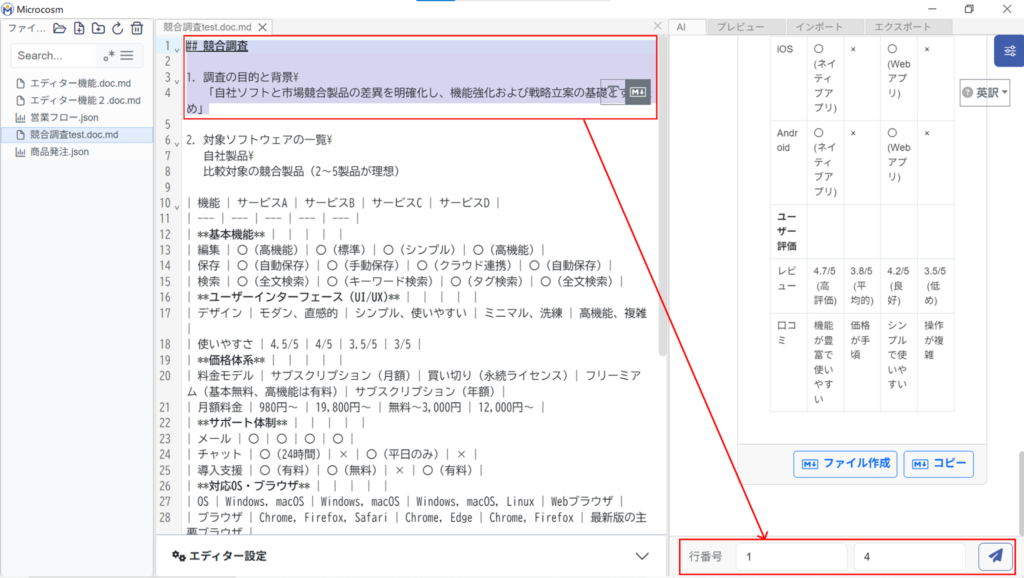
⑤ 添削/英訳/和訳/要約の場合
操作方法は添削/英訳/和訳/要約すべて共通です。英訳を例に記載します。
Markdownを選択し、英訳をしたい行を選択してください。
選択をすると、右下に選択行が出て来ます。
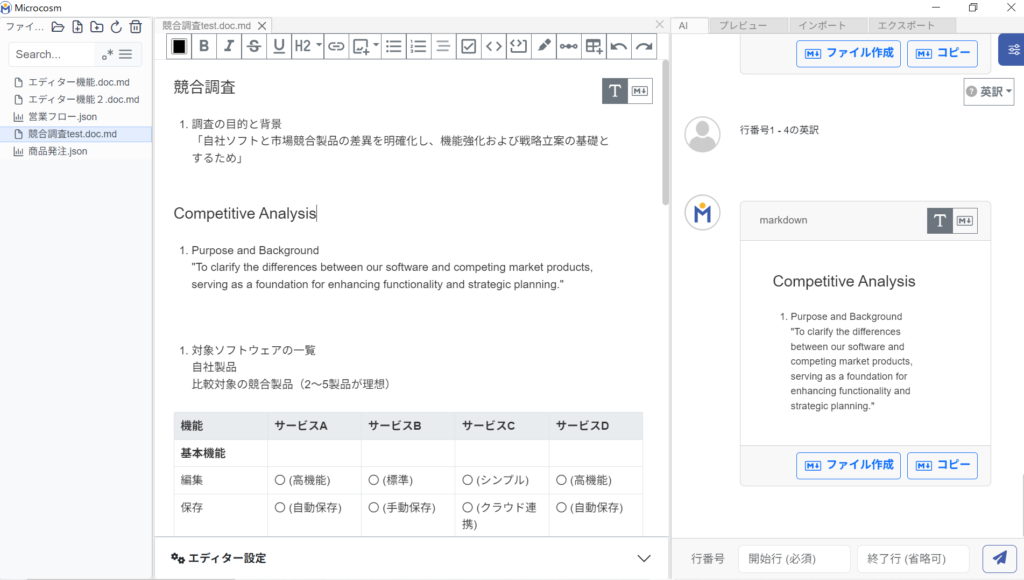
⑥ 手順②を参考に活用できます。
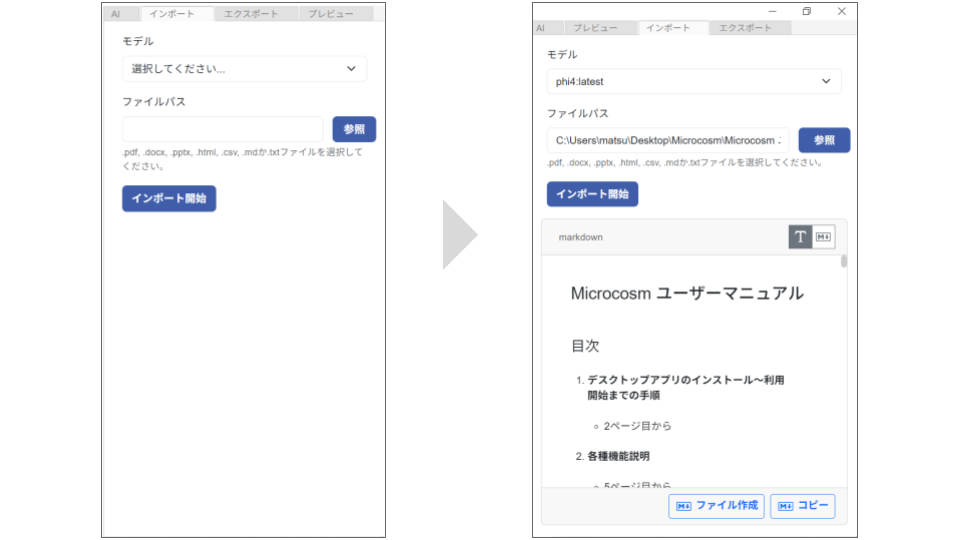
▼インポート手順
① モデルを選択します。
② インポートをしたいファイルのパスを選択し、をクリックしてください。
③ または
を適用してください。
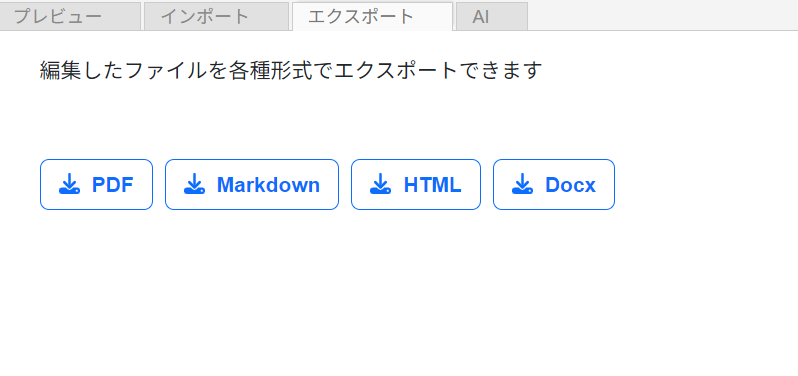
▼エクスポート
PDF/Markdown/HTML/Docx形式で、編集したファイルをエクスポートできます。
▼グラフ
【グラフ作成手順】
①![]() をクリックし、任意のグラフタイトル名を入力し、グラフの見せ方を選択します。グラフタイトルは
をクリックし、任意のグラフタイトル名を入力し、グラフの見せ方を選択します。グラフタイトルは![]() で後から変更できます。
で後から変更できます。
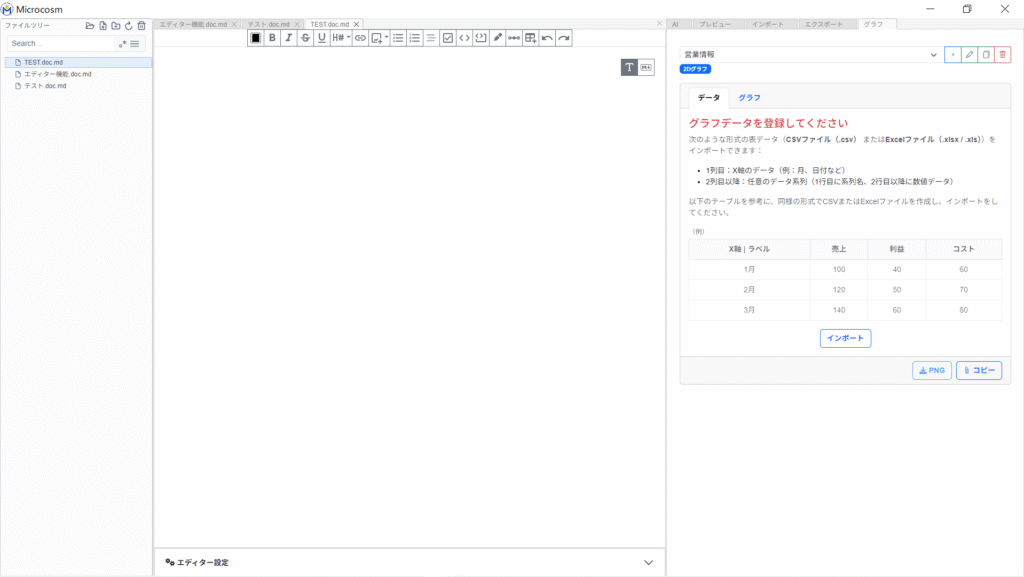
② ![]() をクリックして、グラフにしたいデータをインポートします。
をクリックして、グラフにしたいデータをインポートします。
③ データのインポート後に「グラフ」タブを選択すると、データを元にしたグラフが表示されます。
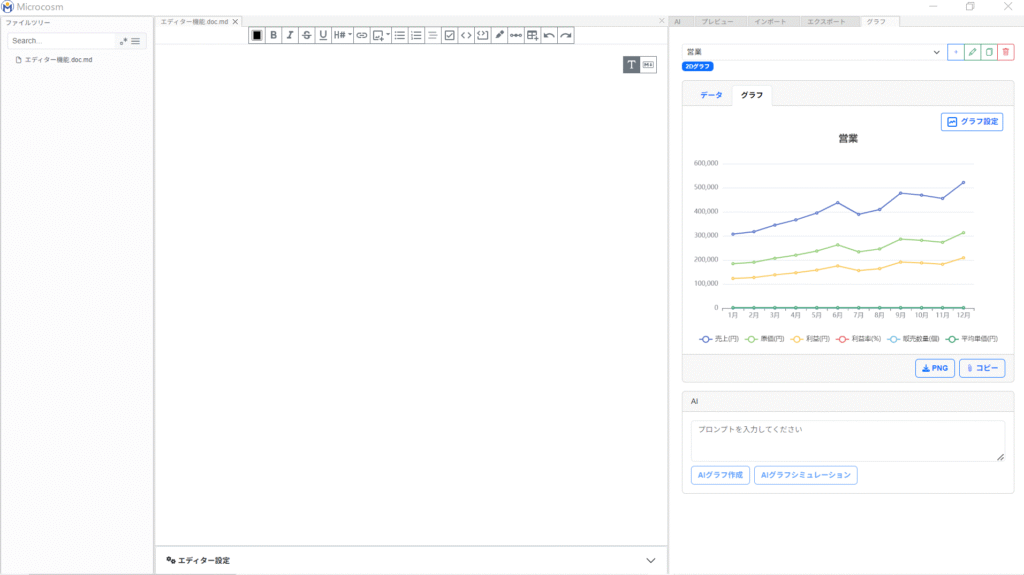
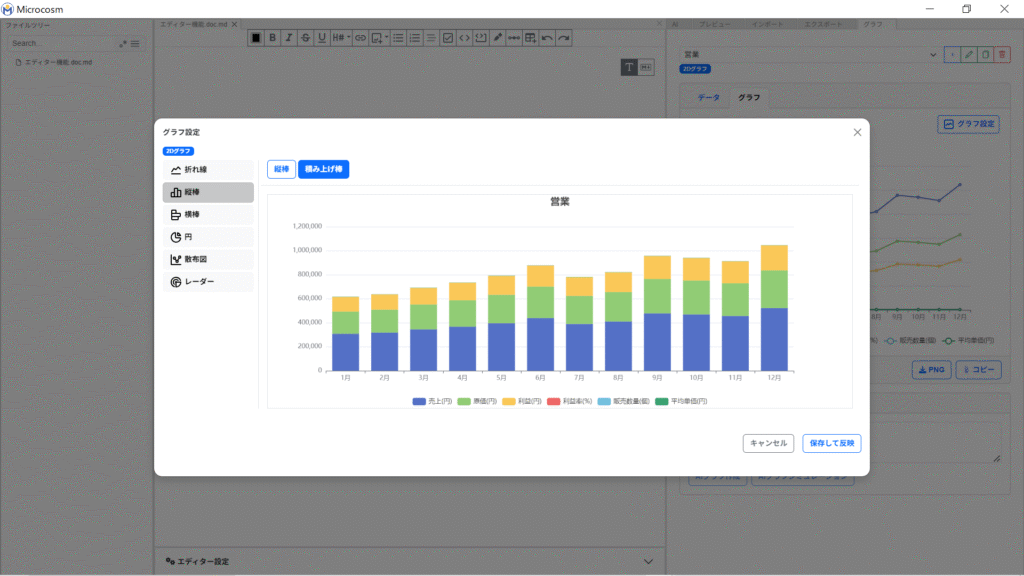
![]() をクリックすると、グラフの種類を折れ線/縦棒/横棒/円/散布図/レーダー(2D)、3D棒/3D散布図(3D)の中から選択することができます。
をクリックすると、グラフの種類を折れ線/縦棒/横棒/円/散布図/レーダー(2D)、3D棒/3D散布図(3D)の中から選択することができます。
以下のAIのボタンを使用し、インポートしたデータを元に新たなデータでグラフを作成することができます。
![]() :データの集計・抽出したグラフを作成することができます。
:データの集計・抽出したグラフを作成することができます。
![]() :予測データのグラフを作成することができます。
:予測データのグラフを作成することができます。
また、作成したグラフを以下のように活用できます。
![]() :PNG形式の画像としてダウンロードすることができます。
:PNG形式の画像としてダウンロードすることができます。
![]() :ボタンをクリックすると、グラフデータをコピーします。データ編集画面のマークダウンに貼り付けることで活用ができます。
:ボタンをクリックすると、グラフデータをコピーします。データ編集画面のマークダウンに貼り付けることで活用ができます。
![]() :グラフを複製することができます。同じデータで別のグラフの種類を作成して保存しておきたい場合に、複製をしておくことで同データで別種のグラフを保存することができます。
:グラフを複製することができます。同じデータで別のグラフの種類を作成して保存しておきたい場合に、複製をしておくことで同データで別種のグラフを保存することができます。
![]() :グラフ自体を削除することができます。
:グラフ自体を削除することができます。
4-4. ナレッジビュー機能
ナレッジビュー機能は、デバイス内にあるファイルから情報を直接呼び出すことができたり、AIで仮想のファイルツリーを作成して情報を整理することができる機能です。

| ① フォルダ選択 | 表示したいフォルダを選択します。 |
| ② フォルダ作成 | ツリー上に仮想のフォルダを新規作成します。ファイルをドラッグアンドドロップで移動することができます。 |
| ③ ドライブ連携 | 開発中の機能です。 |
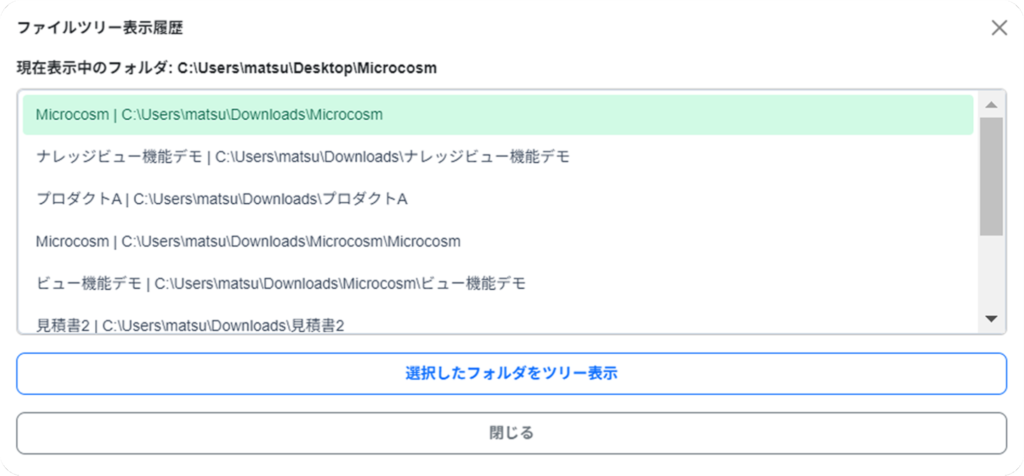
| ④ ファイルツリー表示履歴 | ツリー表示の履歴を確認できます。 |
| ⑤ ディレクトリ開閉 | ツリー表示されたフォルダをすべて開いたり閉じたりすることができます。 |
| ⑥ ファイル/フォルダ削除 | 仮想ツリー上の選択したファイル/フォルダを削除します。 デバイス内のファイル/フォルダは削除されません。 |
| ⑦ ナレッジビュー | |
| ⑧全検索回答 | |
| ⑨ ツリー選択 | 複数のツリーを作成した場合、ツリーを選択できます。初期はデフォルトツリーとなっています。 |
| ⑩ アクション | 新規作成:名称を付け、新しいツリーを作成します。 名称変更:ツリーの名称を変更します。 削除:ツリーを削除します。 デフォルトに戻す:選択したツリーの構成をデフォルトに戻します。 |
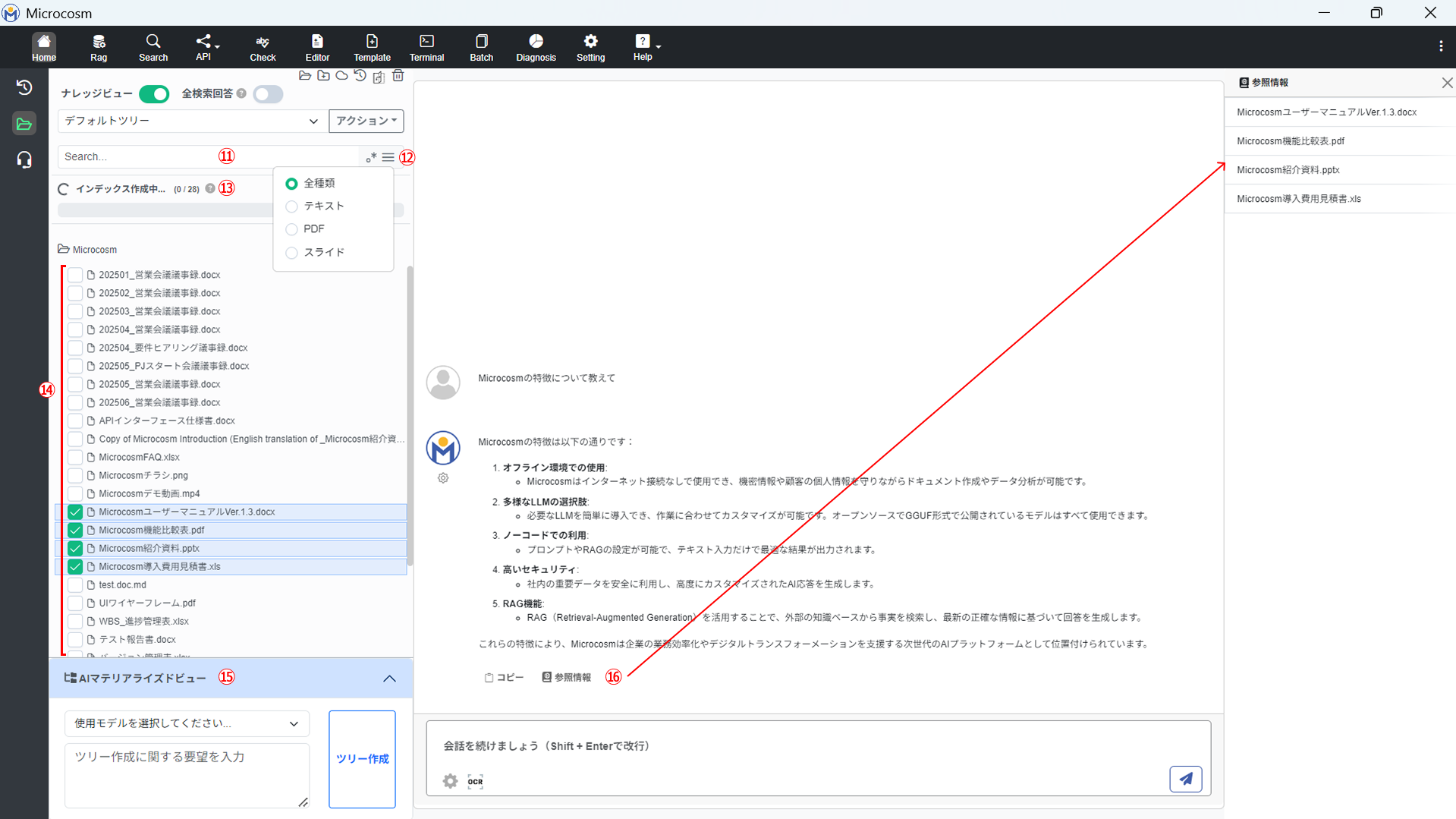
| ⑪ 検索バー | ファイルツリー内のファイル/フォルダを各名称で検索します。 正規表現:特定の文字列のパターンを表現するための表記でテキストを検索することができます(エンジニア向け)。 |
| ⑫ ファイル形式フィルター | 全種類:すべてのファイル形式を表示します。 テキスト:.txt形式ファイルのみを表示します。 PDF:.pdf形式ファイルのみを表示します。 スライド:.pptx形式ファイルのみを表示します。 |
| ⑬ インデックス更新進捗バー | インデックスを作成/更新する際に表示されます。各ユーザーがMicrocosmを起動し、ナレッジビューを表示したタイミングで差分チェックを実行します。 |
| ⑭ ディレクトリツリー | 選択したディレクトリ内のファイル/フォルダと同じ並びを仮想ツリーで表示します。 |
| ⑮ AIマテリアライズビュー | 表示しているツリーをAIで自動整理することができます。 |
| ⑯ 参照情報 | 回答を生成するにあたって、選択したファイルからどの部分を参照したのかを確認することができます。 |
4-4-1. ファイルツリー表示履歴画面
4-4-2. ナレッジビュー機能アクションの各画面
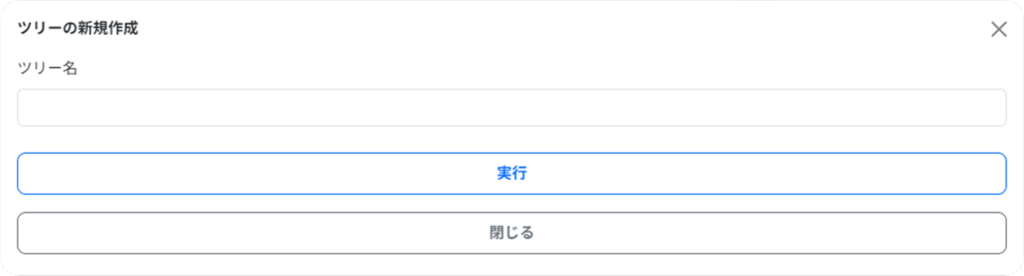
▼新規作成
▼名称変更
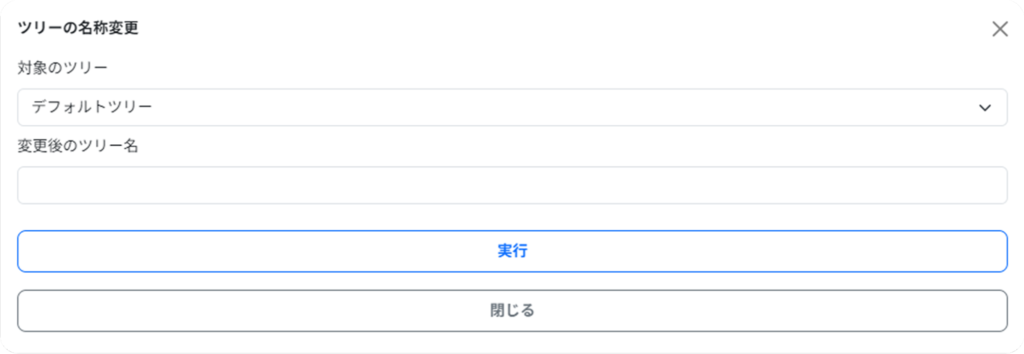
| 対象のツリー | 任意のツリーを選択します。 |
| 変更後のツリー名 | 任意のツリー名を入力します。 |
4-4-3. 参照情報画面
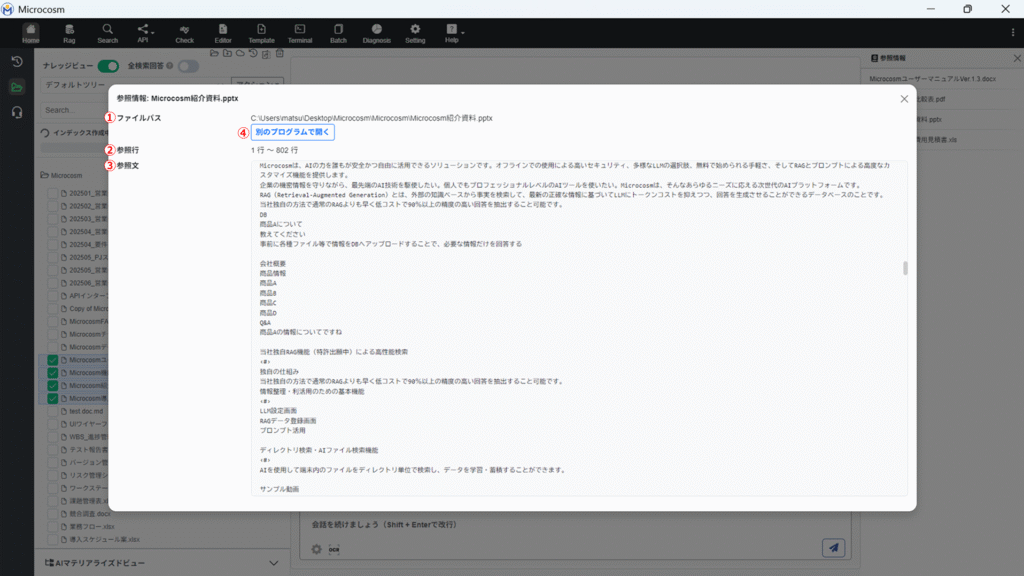
| ① ファイルパス | 参照したファイルのパスを確認できます。 |
| ② 参照行 | ファイル内の参照した行を確認できます。 |
| ③ 参照文 | ファイル内の参照した文を表示します。 |
| ④ | 参照したファイルを開きます。 |
4-4-4. ナレッジビュー機能操作方法
フォルダ選択アイコンより、任意のフォルダを選択します。
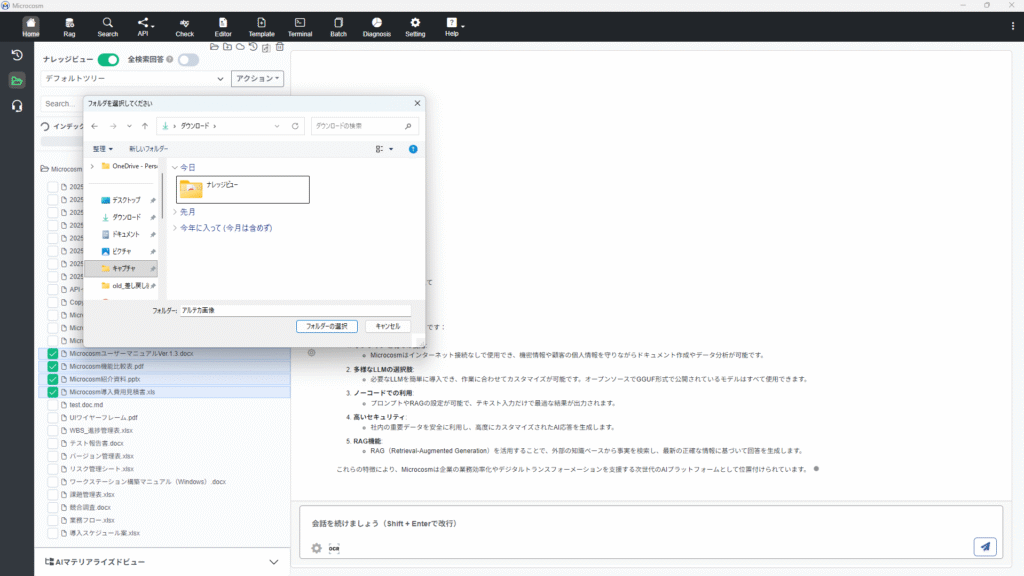
選択したフォルダ内のファイルが仮想のツリー状に表示されます。

表示されたツリーのファイルを選択し、設問入力フォームに質問を入力します。ファイルを選択するとナレッジビューボタンは自動的にオンになります。
▼AIマテリアライズビュー活用方法
モデルを選択し、指示した内容をもとに仮想ツリー内のファイル名のみ参照して、選択したモデルがツリーを自動構築します。変化するツリーは仮想のため、実際のデバイス内のフォルダ内のファイル/フォルダの配置は変化しません。


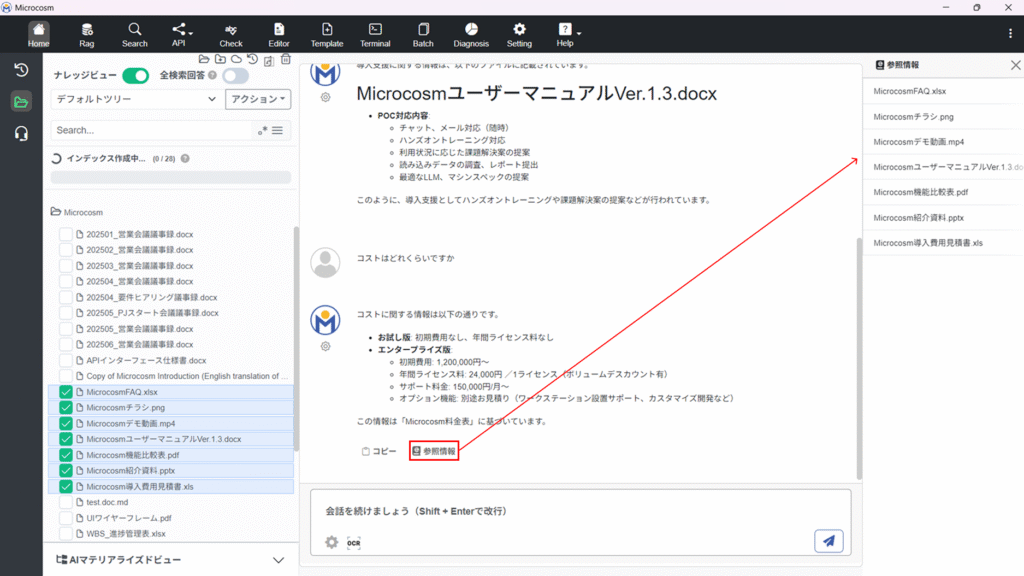
▼参照情報確認方法
ファイルを選択して回答生成をした後に出現する、「参照情報」アイコンを押してください。
画面右側に参照したファイル名が表示されます。
表示されたファイル名をクリックすると、4-4-3. 参照情報画面が表示されます。
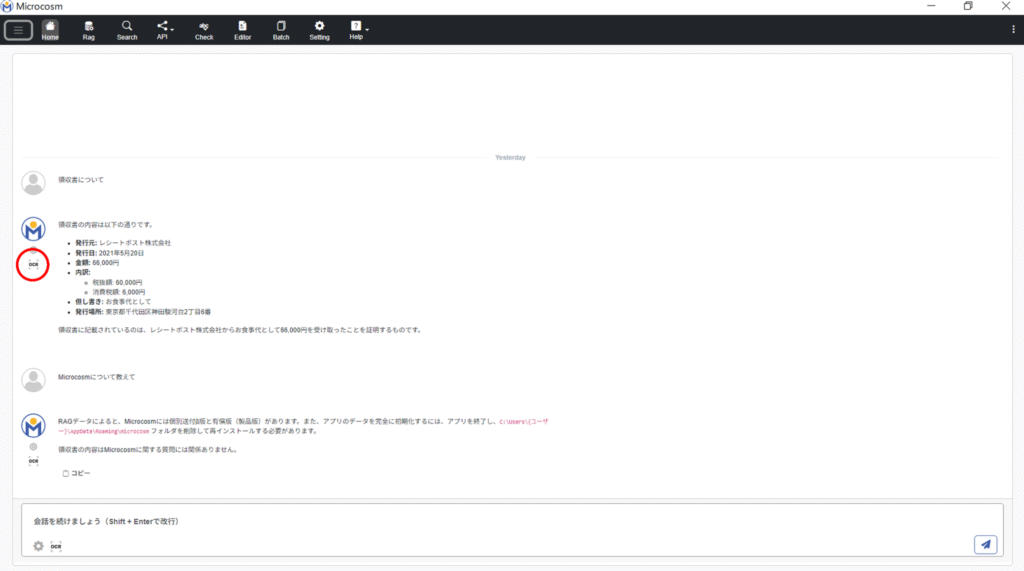
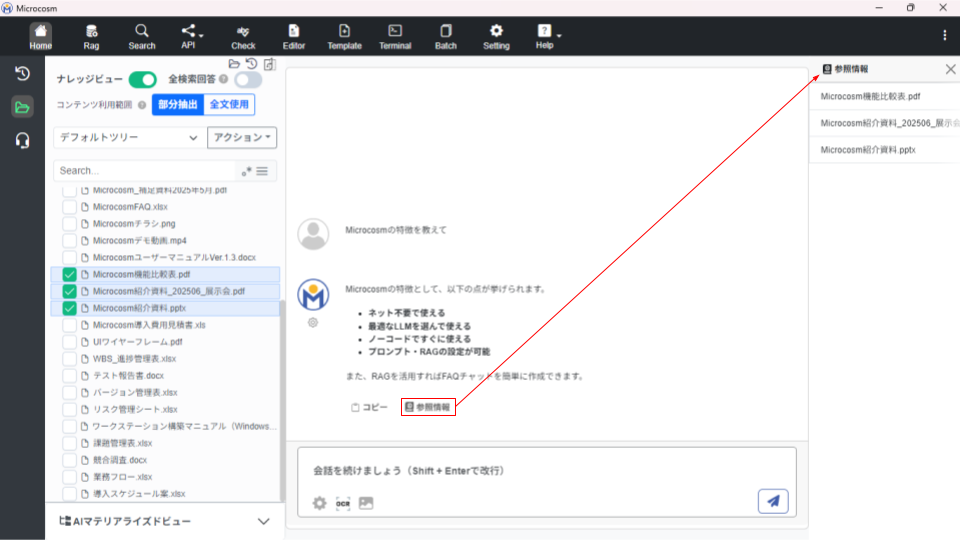
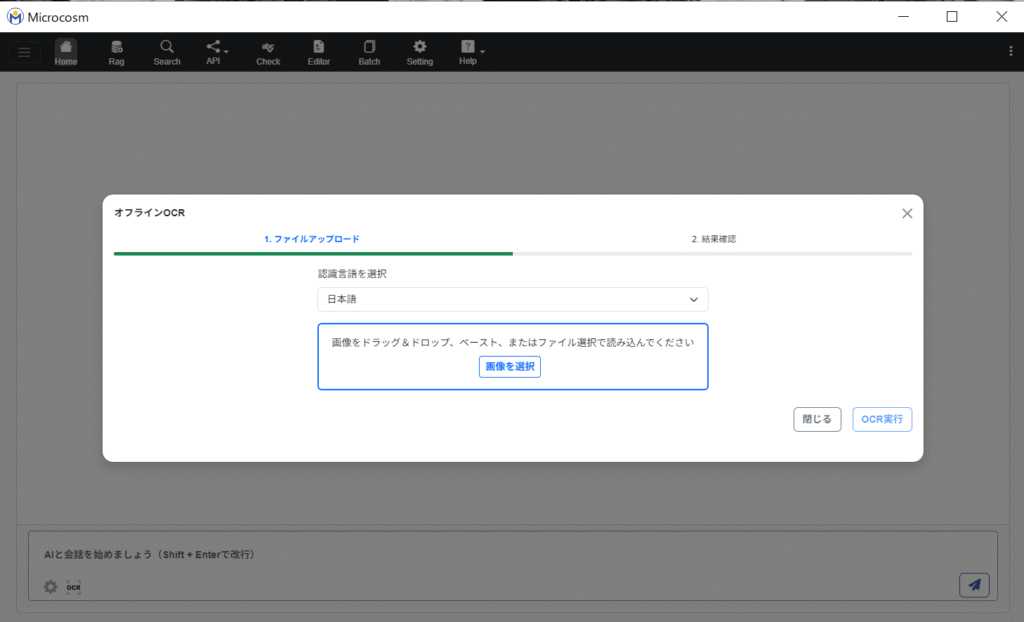
4-5. OCR機能
アップロードした画像を読み取り、テキスト化をする機能になります。
| 認識言語を選択 | 読み取る言語を選択します。 日本語:左上から下へ横書きの日本語を読み取る場合。 日本語(縦読み):右から左へ縦書きの日本語を読み取る場合。 英語:英語を読み取る場合。 |
| 画像を選択 | 青い枠線内に画像をドラッグアンドドロップ、ペースト、または |
| OCRモーダルウィンドウを閉じます。 | |
| アップロードしたファイルのOCR読み取りを開始します。 |
4-5-1. OCR機能操作方法
ホーム画面より、![]() をクリックします。
をクリックします。

読み取る言語を選択します。
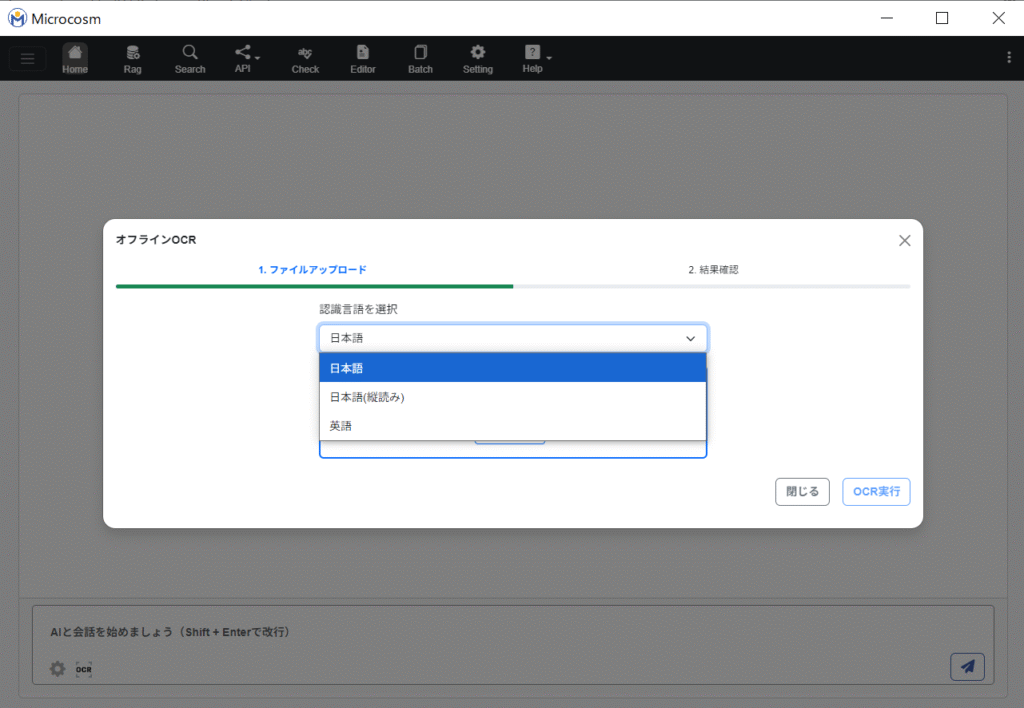
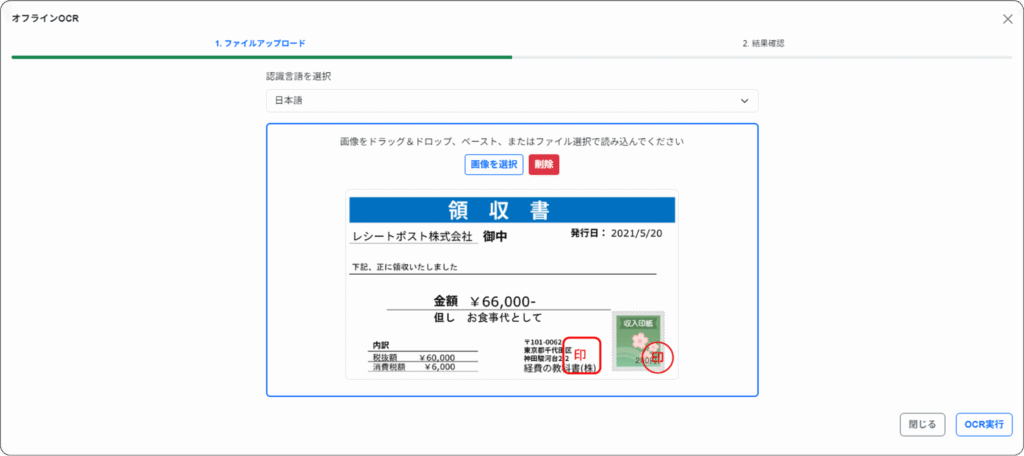
読み取りたい画像をアップロードし、![]() をクリックします。
をクリックします。
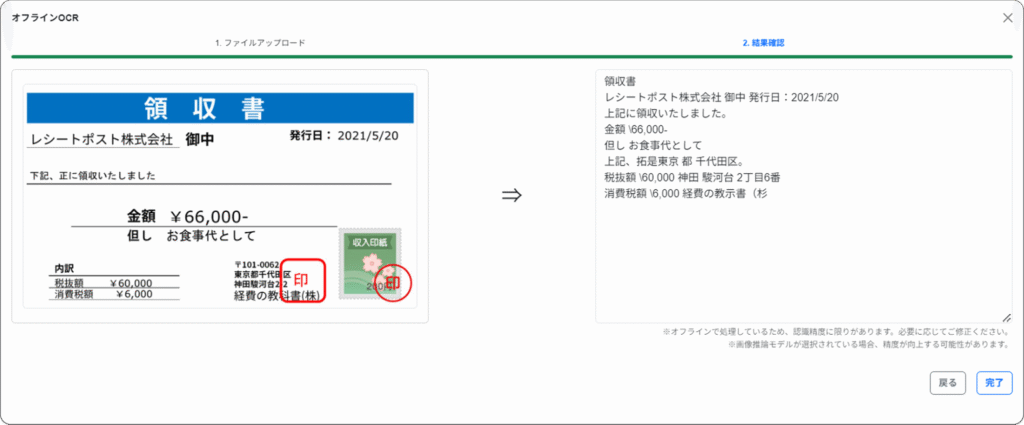
読み取り後、表示される結果を確認し![]() をクリックします。
をクリックします。
ホーム画面へ戻り、![]() が
が![]() になっていることを確認してください。OCRで読み取ったテキストを元に回答ができます。
になっていることを確認してください。OCRで読み取ったテキストを元に回答ができます。
OCRデータ結果は、Microcosmアイコンの下側に表示される、![]() より確認することができます。
より確認することができます。